I continue to work on my autonomous email agent created with Copilot Studio. a recent addition is that now you might get a response that includes something like this at the end of the information returned:
It is a suggestion for an improved prompt to generate better answers based on the original question.
The reason I created this was I noticed many submissions were not writing ‘good’ prompts. In fact, most submissions seem better suited to search engines than for AI. The easy solution was to get Copilot to suggest how to ask better questions.
This report examines each setting in the provided Intune Windows 10/11 compliance policy JSON and evaluates whether it represents best practice for strong security on a Windows device. For each setting, we explain its purpose, configuration options, and why the chosen value helps ensure maximum security.
Device Health Requirements (Boot Security & Encryption)
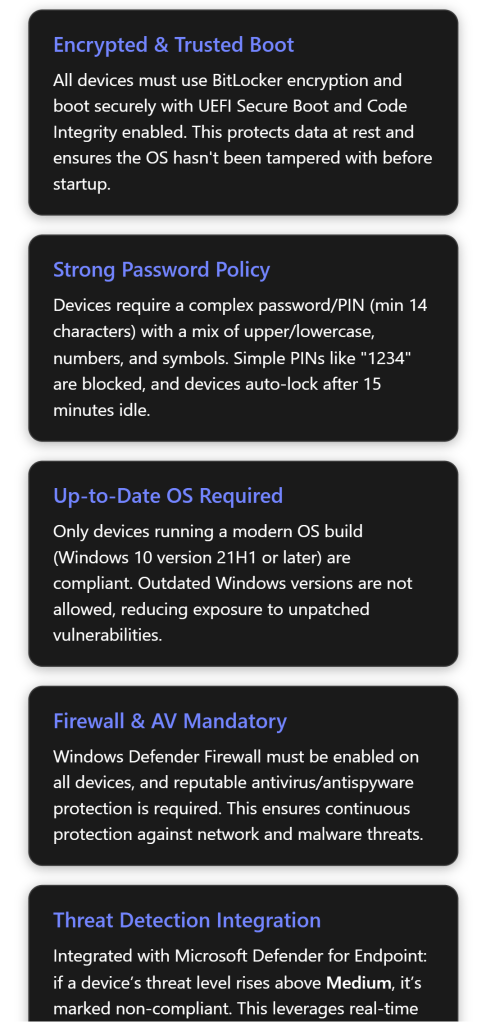
Require BitLocker – BitLocker Drive Encryption is mandated on the OS drive (Require BitLocker: Yes). BitLocker uses the system’s TPM to encrypt all data on disk and locks encryption keys unless the system’s integrity is verified at boot[1]. The policy setting “Require BitLocker” ensures that data at rest is protected – if a laptop is lost or stolen, an unauthorized person cannot read the disk contents without proper authorization[1]. Options:Not configured (default, don’t check encryption) or Require (device must be encrypted with BitLocker)[1]. Setting this to “Require” is considered best practice for strong security, as unencrypted devices pose a high data breach risk[1]. In our policy JSON, BitLocker is indeed required[2], aligning with industry recommendations to encrypt all sensitive devices.
Require Secure Boot – This ensures the PC is using UEFI Secure Boot (Require Secure Boot: Yes). Secure Boot forces the system to boot only trusted, signed bootloaders. During startup, the UEFI firmware will verify that bootloader and critical kernel files are signed by a trusted authority and have not been modified[1]. If any boot file is tampered with (e.g. by a bootkit or rootkit malware), Secure Boot will prevent the OS from booting[1]. Options: Not configured (don’t enforce) or Require (must boot in secure mode)[1]. The policy requires Secure Boot[2], which is a best-practice security measure to maintain boot-time integrity. This setting helps ensure the device boots to a trusted state and is not running malicious firmware or bootloaders[1]. Requiring Secure Boot is recommended in frameworks like Microsoft’s security baselines and the CIS benchmarks for Windows, provided the hardware supports it (most modern PCs do)[1].
Require Code Integrity – Code integrity (a Device Health Attestation setting) validates the integrity of Windows system binaries and drivers each time they are loaded into memory. Enforcing this (Require code integrity: Yes) means that if any system file or driver is unsigned or has been altered by malware, the device will be reported as non-compliant[1]. Essentially, it helps detect kernel-level rootkits or unauthorized modifications to critical system components. Options: Not configured or Require (must enforce code integrity)[1]. The policy requires code integrity to be enabled[2], which is a strong security practice. This setting complements Secure Boot by continuously verifying system integrity at runtime, not just at boot. Together, Secure Boot and Code Integrity reduce the risk of persistent malware or unauthorized OS tweaks going undetected[1].
By enabling BitLocker, Secure Boot, and Code Integrity, the compliance policy ensures devices have a trusted startup environment and encrypted storage – foundational elements of a secure endpoint. These Device Health requirements align with best practices like Microsoft’s recommended security baselines (which also require BitLocker and Secure Boot) and are critical to protect against firmware malware, bootkits, and data theft[1][1]. Note: Devices that lack a TPM or do not support Secure Boot will be marked noncompliant, meaning this policy effectively excludes older, less secure hardware from the compliant device pool – which is intentional for a high-security stance.
Device OS Version Requirements
Minimum OS version – This policy defines the oldest Windows OS build allowed on a device. In the JSON, the Minimum OS version is set to 10.0.19043.10000 (which corresponds roughly to Windows 10 21H1 with a certain patch level)[2]. Any Windows device reporting an OS version lower than this (e.g. 20H2 or an unpatched 21H1) will be marked non-compliant. The purpose is to block outdated Windows versions that lack recent security fixes. End users on older builds will be prompted to upgrade to regain compliance[1]. Options: admin can specify any version string; leaving it blank means no minimum enforcement[1]. Requiring a minimum OS version is a best practice to ensure devices have received important security patches and are not running end-of-life releases[1]. The chosen minimum (10.0.19043) suggests that Windows 10 versions older than 21H1 are not allowed, which is reasonable for strong security since Microsoft no longer supports very old builds. This helps reduce vulnerabilities – for example, a device stuck on an early 2019 build would miss years of defenses (like improved ransomware protection in later releases). The policy’s min OS requirement aligns with guidance to keep devices updated to at least the N-1 Windows version or newer.
Maximum OS version – In this policy, no maximum OS version is configured (set to “Not configured”)[2]. That means devices running newer OS versions than the admin initially tested are not automatically flagged noncompliant. This is usually best, because setting a max OS version is typically used only to temporarily block very new OS upgrades that might be unapproved. Leaving it not configured (no upper limit) is often a best practice unless there’s a known issue with a future Windows release[1]. In terms of strong security, not restricting the maximum OS allows devices to update to the latest Windows 10/11 feature releases, which usually improves security. (If an organization wanted to pause Windows 11 adoption, they might set a max version to 10.x temporarily, but that’s a business decision, not a security improvement.) So the policy’s approach – no max version limit – is fine and does align with security best practice in most cases, as it encourages up-to-date systems rather than preventing them.
Why enforce OS versions? Keeping OS versions current ensures known vulnerabilities are patched. For example, requiring at least build 19043 means any device on 19042 or earlier (which have known exposures fixed in 19043+) will be blocked until updated[1]. This reduces the attack surface. The compliance policy will show a noncompliant device “OS version too low” with guidance to upgrade[1], helping users self-remediate. Overall, the OS version rules in this policy push endpoints to stay on supported, secure Windows builds, which is a cornerstone of strong device security.
*(The policy also lists “Minimum/Maximum OS version for *mobile devices” with the same values (10.0.19043.10000 / Not configured)[2]. This likely refers to Windows 10 Mobile or Holographic devices. It’s largely moot since Windows 10 Mobile is deprecated, but having the same minimum for “mobile” ensures something like a HoloLens or Surface Hub also requires an up-to-date OS. In our case, both fields mirror the desktop OS requirement, which is fine.)
Configuration Manager Compliance (Co-Management)
Require device compliance from Configuration Manager – This setting is Not configured in the JSON (i.e. it’s left at default)[2]. It applies only if the Windows device is co-managed with Microsoft Endpoint Configuration Manager (ConfigMgr/SCCM) in addition to Intune. Options: Not configured (Intune ignores ConfigMgr’s compliance state) or Require (device must also meet all ConfigMgr compliance policies)[1].
In our policy, leaving it not configured means Intune will not check ConfigMgr status – effectively the device only has to satisfy the Intune rules to be marked compliant. Is this best practice? For purely Intune-managed environments, yes – if you aren’t using SCCM baselines, there’s no need to require this. If an organization is co-managed and has on-premises compliance settings in SCCM (like additional security baselines or antivirus status monitored by SCCM), a strong security stance might enable this to ensure those are met too[1]. However, enabling it without having ConfigMgr compliance policies could needlessly mark devices noncompliant as “not reporting” (Intune would wait for a ConfigMgr compliance signal that might not exist).
So, the best practice depends on context: In a cloud-only or lightly co-managed setup, leaving this off (Not Configured) is correct[1]. If the organization heavily uses Configuration Manager to enforce other critical security settings, then best practice would be to turn this on so Intune treats any SCCM failure as noncompliance. Since this policy likely assumes modern management primarily through Intune, Not configured is appropriate and not a security gap. (Admins should ensure that either Intune covers all needed checks, or if not, integrate ConfigMgr compliance by requiring it. Here Intune’s own checks are quite comprehensive.)
System Security: Password Requirements
A very important part of device security is controlling access with strong credentials. This policy enforces a strict device password/PIN policy under the “System Security” category:
Require a password to unlock – Yes (Required). This means the device cannot be unlocked without a password or PIN. Users must authenticate on wake or login[1]. Options: Not configured (no compliance check on whether a device has a lock PIN/password set) or Require (device must have a lock screen password/PIN)[1]. Requiring a password is absolutely a baseline security requirement – a device with no lock screen PIN is extremely vulnerable (anyone with physical access could get in). The policy correctly sets this to Require[2]. Intune will flag any device without a password as noncompliant, likely forcing the user to set a Windows Hello PIN or password. This is undeniably best practice; all enterprise devices should be password/PIN protected.
Block simple passwords – Yes (Block). “Simple passwords” refers to very easy PINs like 0000 or 1234 or repeating characters. The setting is Simple passwords: Block[1]. When enabled, Intune will require that the user’s PIN/passcode is not one of those trivial patterns. Options: Not configured (allow any PIN) or Block (disallow common simple PINs)[1]. Best practice is to block simple PINs because those are easily guessable if someone steals the device. This policy does so[2], meaning a PIN like “1111” or “12345” would not be considered compliant. Instead, users must choose less predictable codes. This is a straightforward security best practice (also recommended by Microsoft’s baseline and many standards) to defeat casual guessing attacks.
Password type – Alphanumeric. This setting specifies what kinds of credentials are acceptable. “Alphanumeric” in Intune means the user must set a password or PIN that includes a mix of letters and numbers (not just digits)[1]. The other options are “Device default” (which on Windows typically allows a PIN of just numbers) or explicitly Numeric (only numbers allowed)[1]. Requiring Alphanumeric effectively forces a stronger Windows Hello PIN – it must include at least one letter or symbol in addition to digits. The policy sets this to Alphanumeric[2], which is a stronger stance than a simple numeric PIN. It expands the space of possible combinations, making it much harder for an attacker to brute-force or guess a PIN. This is aligned with best practice especially if using shorter PIN lengths – requiring letters and numbers significantly increases PIN entropy. (If a device only allows numeric PINs, a 6-digit PIN has a million possibilities; an alphanumeric 6-character PIN has far more.) By choosing Alphanumeric, the admin is opting for maximum complexity in credentials.
Note: When Alphanumeric is required, Intune enables additional complexity rules (next setting) like requiring symbols, etc. If instead it was set to “Numeric”, those complexity sub-settings would not apply. So this choice unlocks the strongest password policy options[1].
Password complexity requirements – Require digits, lowercase, uppercase, and special characters. This policy is using the most stringent complexity rule available. Under Intune, for alphanumeric passwords/PINs you can require various combinations: the default is “digits & lowercase letters”; but here it’s set to “require digits, lowercase, uppercase, and special characters”[1]. That means the user’s password (or PIN, if using Windows Hello PIN as an alphanumeric PIN) must include at least one lowercase letter, one uppercase letter, one number, and one symbol. This is essentially a classic complex password policy. Options: a range from requiring just some character types up to all four categories[1]. Requiring all four types is generally seen as a strict best practice for high security (it aligns with many compliance standards that mandate a mix of character types in passwords). The idea is to prevent users from choosing, say, all letters or all numbers; a mix of character types increases password strength. Our policy indeed sets the highest complexity level[2]. This ensures credentials are harder to crack via brute force or dictionary attacks, albeit at the cost of memorability. It’s worth noting modern NIST guidance allows passphrases (which might not have all char types) as an alternative, but in many organizations, this “at least one of each” rule remains a common security practice for device passwords.
Minimum password length – 14 characters. This defines the shortest password or PIN allowed. The compliance policy requires the device’s unlock PIN/password to be 14 or more characters long[1]. Fourteen is a relatively high minimum; by comparison, many enterprise policies set min length 8 or 10. By enforcing 14, this policy is going for very strong password length, which is consistent with guidance for high-security environments (some standards suggest 12+ or 14+ characters for administrative or highly sensitive accounts). Options: 1–16 characters can be set (the admin chooses a number)[1]. Longer is stronger – increasing length exponentially strengthens resistance to brute-force cracking. At 14 characters with the complexity rules above, the space of possible passwords is enormous, making targeted cracking virtually infeasible. This is absolutely a best practice for strong security, though 14 might be considered slightly beyond typical user-friendly lengths. It aligns with guidance like using passphrases or very long PINs for device unlock. Our policy’s 14-char minimum[2] indicates a high level of security assurance (for context, the U.S. DoD STIGs often require 15 character passwords on Windows – 14 is on par with such strict standards).
Maximum minutes of inactivity before password is required – 15 minutes. This controls the device’s idle timeout, i.e. how long a device can sit idle before it auto-locks and requires re-authentication. The policy sets 15 minutes[2]. Options: The admin can define a number of minutes; when not set, Intune doesn’t enforce an inactivity lock (though Windows may have its own default)[1]. Requiring a password after 15 minutes of inactivity is a common security practice to balance security with usability. It means if a user steps away, at most 15 minutes can pass before the device locks itself and demands a password again. Shorter timers (5 or 10 min) are more secure (less window for an attacker to sit at a logged-in machine), whereas longer (30+ min) are more convenient but risk someone opportunistically using an unlocked machine. 15 minutes is a reasonable best-practice value for enterprises – it’s short enough to limit unauthorized access, yet not so short that it frustrates users excessively. Many security frameworks recommend 15 minutes or less for session locks. This policy’s 15-minute setting is in line with those recommendations and thus supports a strong security posture. It ensures a lost or unattended laptop will lock itself in a timely manner, reducing the chance for misuse.
Password expiration (days) – 365 days. This setting forces users to change their device password after a set period. Here it is one year[2]. Options: 1–730 days or not configured[1]. Requiring password change every 365 days is a moderate approach to password aging. Traditional policies often used 90 days, but that can lead to “password fatigue.” Modern NIST guidelines actually discourage frequent forced changes (unless there’s evidence of compromise) because overly frequent changes can cause users to choose weaker passwords or cycle old ones. However, annual expiration (365 days) is relatively relaxed and can be seen as a best practice in some environments to ensure stale credentials eventually get refreshed[1]. It’s basically saying “change your password once a year.” Many organizations still enforce yearly or biannual password changes as a precaution. In terms of strong security, this setting provides some safety net (in case a password was compromised without the user knowing, it won’t work indefinitely). It’s not as critical as the other settings; one could argue that with a 14-char complex password, forced expiration isn’t strictly necessary. But since it’s set, it reflects a security mindset of not letting any password live forever. Overall, 365 days is a reasonable compromise – it’s long enough that users can memorize a strong password, and short enough to ensure a refresh if by chance a password leaked over time. This is largely aligned with best practice, though some newer advice would allow no expiration if other controls (like multifactor auth) are in place. In a high-security context, annual changes remain common policy.
Number of previous passwords to prevent reuse – 5. This means when a password is changed (due to expiration or manual change), the user cannot reuse any of their last 5 passwords[1]. Options: Typically can set a value like 1–50 previous passwords to disallow. The policy chose 5[2]. This is a standard part of password policy – preventing reuse of recent passwords helps ensure that when users do change their password, they don’t just alternate between a couple of favorites. A history of 5 is pretty typical in best practices (common ranges are 5–10) to enforce genuine password updates. This setting is definitely a best practice in any environment with password expiration – otherwise users might just swap back and forth between two passwords. By disallowing the last 5, it will take at least 6 cycles (in this case 6 years, given 365-day expiry) before one could reuse an old password, by which time it’s hoped that password would have lost any exposure or the user comes up with a new one entirely. The policy’s value of 5 is fine and commonly recommended.
Require password when device returns from idle state – Yes (Required). This particularly applies to mobile or Holographic devices, but effectively it means a password is required upon device wake from an idle or sleep state[1]. On Windows PCs, this corresponds to the “require sign-in on wake” setting. Since our idle timeout is 15 minutes, this ensures that when the device is resumed (after sleeping or being idle past that threshold), the user must sign in again. Options: Not configured or Require[1]. The policy sets it to Require[2], which is certainly what we want – it’d be nonsensical to have all the above password rules but then not actually lock on wake! In short, this enforces that the password/PIN prompt appears after the idle period or sleep, which is absolutely a best practice. (Without this, a device could potentially wake up without a login prompt, which would undermine the idle timeout.) Windows desktop devices are indeed impacted by this on next sign-in after an idle, as noted in docs[1]. So this setting ties the loop on the secure password policy: not only must devices have strong credentials, but those credentials must be re-entered after a period of inactivity, ensuring continuous protection.
Summary of Password Policy: The compliance policy highly prioritizes strong access control. It mandates a login on every device (no password = noncompliant), and that login must be complex (not guessable, not short, contains diverse characters). The combination of Alphanumeric, 14+ chars, all character types, no simple PINs is about as strict as Windows Intune allows for user sign-in credentials[1][2]. This definitely meets the definition of best practice for strong security – it aligns with standards like CIS benchmarks which also suggest enforcing password complexity and length. Users might need to use passphrases or a mix of PIN with letters to meet this, but that is intended. The idle lock at 15 minutes and requirement to re-authenticate on wake ensure that even an authorized session can’t be casually accessed if left alone for long. The annual expiration and password history add an extra layer to prevent long-term use of any single password or recycling of old credentials, which is a common corporate security requirement.
One could consider slight adjustments: e.g., some security frameworks (like NIST SP 800-63) would possibly allow no expiration if the password is sufficiently long and unique (to avoid users writing it down or making minor changes). However, given this is a “strong security” profile, the chosen settings err on the side of caution, which is acceptable. Another improvement for extreme security could be shorter idle time (like 5 minutes) to lock down faster, but 15 minutes is generally acceptable and strikes a balance. Overall, these password settings significantly harden the device against unauthorized access and are consistent with best practices.
Encryption of Data Storage on Device
Require encryption of data storage on device – Yes (Required). Separate from the BitLocker requirement in Device Health, Intune also has a general encryption compliance rule. Enabling this means the device’s drives must be encrypted (with BitLocker, in the case of Windows) or else it’s noncompliant[1]. In our policy, “Encryption: Require” is set[2]. Options: Not configured or Require[1]. This is effectively a redundant safety net given BitLocker is also specifically required. According to Microsoft, the “Encryption of data storage” check looks for any encryption present (on the OS drive), and specifically on Windows it checks BitLocker status via a device report[1]. It’s slightly less robust than the Device Health attestation for BitLocker (which needs a reboot to register, etc.), but it covers the scenario generally[1].
From a security perspective, requiring device encryption is unquestionably best practice. It ensures that if a device’s drive isn’t encrypted (for example, BitLocker not enabled or turned off), the device will be flagged. This duplicates the BitLocker rule; having both doesn’t hurt – in fact, Microsoft documentation suggests the simpler encryption compliance might catch the state even if attestation hasn’t updated (though the BitLocker attestation is more reliable for TPM verification of encryption)[1].
In practice, an admin could use one or the other. This policy enables both, which indicates a belt-and-suspenders approach: either way, an unencrypted device will not slip through. This is absolutely aligned with strong security – all endpoints must have storage encryption, mitigating the risk of data exposure from lost or stolen hardware. Modern best practices (e.g. CIS, regulatory requirements like GDPR for laptops with personal data) often mandate full-disk encryption; here it’s enforced twice. The documentation even notes that relying on the BitLocker-specific attestation is more robust (it checks at the TPM level and knows the device booted with BitLocker enabled)[1][1]. The generic encryption check is a bit more broad but for Windows equates to BitLocker anyway. The key point is the policy requires encryption, which we already confirmed is a must-have security control. If BitLocker was somehow not supported on a device (very rare on Windows 10/11, since even Home edition has device encryption now), that device would simply fail compliance – again, meaning only devices capable of encryption and actually encrypted are allowed, which is appropriate for a secure environment.
(Note: Since both “Require BitLocker” and “Require encryption” are turned on, an Intune admin should be aware that a device might show two noncompliance messages for essentially the same issue if BitLocker is off. Users would see that they need to turn on encryption to comply. Once BitLocker is enabled and the device rebooted, both checks will pass[1][1]. The rationale for using both might be to ensure that even if the more advanced attestation didn’t report, the simpler check would catch it.)
This section of the policy ensures that essential security features of Windows are active:
Firewall – Require. The policy mandates that the Windows Defender Firewall is enabled on the device (Firewall: Require)[1]. This means Intune will mark the device noncompliant if the firewall is turned off or if a user/app tries to disable it. Options: Not configured (do not check firewall status) or Require (firewall must be on)[1]. Requiring the firewall is definitely best practice – a host-based firewall is a critical first line of defense against network-based attacks. The Windows Firewall helps block unwanted inbound connections and can enforce outbound rules as well. By ensuring it’s always on (and preventing users from turning it off), the policy guards against scenarios where an employee might disable the firewall and expose the machine to threats[1]. This setting aligns with Microsoft recommendations and CIS Benchmarks, which also advise that Windows Firewall be enabled on all profiles. Our policy sets it to Require[2], which is correct for strong security. (One thing to note: if there were any conflicting GPO or config that turns the firewall off or allows all traffic, Intune would consider that noncompliant even if Intune’s own config profile tries to enable it[1] – essentially, Intune checks the effective state. Best practice is to avoid conflicts and keep the firewall defaults to block inbound unless necessary[1].)
Trusted Platform Module (TPM) – Require. This check ensures the device has a TPM chip present and enabled (TPM: Require)[1]. Intune will look for a TPM security chip and mark the device noncompliant if none is found or it’s not active. Options: Not configured (don’t verify TPM) or Require (TPM must exist)[1]. TPM is a hardware security module used for storing cryptographic keys (like BitLocker keys) and for platform integrity (measured boot). Requiring a TPM is a strong security stance because it effectively disallows devices that lack modern hardware security support. Most Windows 10/11 PCs do have TPM 2.0 (Windows 11 even requires it), so this is feasible and aligns with best practices. It ensures features like BitLocker are using TPM protection and that the device can do hardware attestation. The policy sets TPM to required[2], which is a best practice consistent with Microsoft’s own baseline (they recommend excluding non-TPM machines, as those are typically older or less secure). By enforcing this, you guarantee that keys and sensitive operations can be hardware-isolated. A device without TPM could potentially store BitLocker keys in software (less secure) or not support advanced security like Windows Hello with hardware-backed credentials. So from a security viewpoint, this is the right call. Any device without a TPM (or with it disabled) will need remediation or replacement, which is acceptable in a high-security environment. This reflects a zero-trust hardware approach: only modern, TPM-equipped devices can be trusted fully[1].
Antivirus – Require. The compliance policy requires that antivirus protection is active and up-to-date on the device (Antivirus: Require)[1]. Intune checks the Windows Security Center status for antivirus. If no antivirus is registered, or if the AV is present but disabled/out-of-date, the device is noncompliant[1]. Options: Not configured (don’t check AV) or Require (must have AV on and updated)[1]. It’s hard to overstate the importance of this: running a reputable, active antivirus/antimalware is absolutely best practice on Windows. The policy’s requirement means every device must have an antivirus engine running and not report any “at risk” state. Windows Defender Antivirus or a third-party AV that registers with Security Center will satisfy this. If a user has accidentally turned off real-time protection or if the AV signatures are old, Intune will flag it[1]. Enforcing AV is a no-brainer for strong security. This matches all industry guidance (e.g., CIS Controls highlight the need for anti-malware on all endpoints). Our policy does enforce it[2].
Antispyware – Require. Similar to antivirus, this ensures anti-spyware (malware protection) is on and healthy (Antispyware: Require)[1]. In modern Windows terms, “antispyware” is essentially covered by Microsoft Defender Antivirus as well (Defender handles viruses, spyware, all malware). But Intune treats it as a separate compliance item to check in Security Center. This setting being required means the anti-malware software’s spyware detection component (like Defender’s real-time protection for spyware/PUPs) must also be enabled and not outdated[1]. Options: Not configured or Require, analogous to antivirus[1]. The policy sets it to Require[2]. This is again best practice – it ensures comprehensive malware protection is in place. In effect, having both AV and antispyware required just double-checks that the endpoint’s security suite is fully active. If using Defender, it covers both; if using a third-party suite, as long as it reports to Windows Security Center for both AV and antispyware status, it will count. This redundancy helps catch any scenario where maybe virus scanning is on but spyware definitions are off (though that’s rare with unified products). For our purposes, requiring antispyware is simply reinforcing the “must have anti-malware” rule – clearly aligned with strong security standards.
Collectively, these Device Security settings (Firewall, TPM, AV, antispyware) ensure that critical protective technologies are in place on every device:
The firewall requirement guards against network attacks and unauthorized connections[1].
The TPM requirement ensures hardware-based security for encryption and identity[1].
The AV/antispyware requirements ensure continuous malware defense and that no device is left unprotected against viruses or spyware[1].
All are definitely considered best practices. In fact, running without any of these (no firewall, no AV, etc.) would be considered a serious security misconfiguration. This policy wisely enforces all of them. Any device not meeting these (e.g., someone attempts to disable Defender Firewall or uninstall AV) will get swiftly flagged, which is exactly what we want in a secure environment.
*(Side note: The policy’s reliance on Windows Security Center means it’s vendor-agnostic; e.g., if an organization uses Symantec or another AV, as long as that product reports a good status to Security Center, Intune will see the device as compliant for AV/antispyware. If a third-party AV is used that *disables* Windows Defender, that’s fine because Security Center will show another AV is active. The compliance rule will still require that one of them is active. So this is a flexible but strict enforcement of “you must have one”.)*
Microsoft Defender Anti-malware Requirements
The policy further specifies settings under Defender (Microsoft Defender Antivirus) to tighten control of the built-in anti-malware solution:
Microsoft Defender Antimalware – Require. This means the Microsoft Defender Antivirus service must be running and cannot be turned off by the user[1]. If the device’s primary AV is Defender (as is default on Windows 10/11 when no other AV is installed), this ensures it stays on. Options: Not configured (Intune doesn’t ensure Defender is on) or Require (Defender AV must be enabled)[1]. Our policy sets it to Require[2], which is a strong choice. If a third-party AV is present, how does this behave? Typically, when a third-party AV is active, Defender goes into a passive mode but is still not “disabled” in Security Center terms – or it might hand over status. This setting primarily aims to prevent someone from turning off Defender without another AV in place. Requiring Defender antivirus to be on is a best practice if your organization relies on Defender as the standard AV. It ensures no one (intentionally or accidentally) shuts off Windows’ built-in protection[1]. It essentially overlaps with the “Antivirus: Require” setting, but is more specific. The fact that both are set implies this environment expects to use Microsoft Defender on all machines (which is common for many businesses). In a scenario where a user installed a 3rd party AV that doesn’t properly report to Security Center, having this required might actually conflict (because Defender might register as off due to third-party takeover, thus Intune might mark noncompliant). But assuming standard behavior, if third-party AV is present and reporting, Security Center usually shows “Another AV is active” – Intune might consider the AV check passed but the “Defender Antimalware” specifically could possibly see Defender as not the active engine and flag it. In any case, for strong security, the ideal is to have a consistent AV (Defender) across all devices. So requiring Defender is a fine security best practice, and our policy reflects that intention. It aligns with Microsoft’s own baseline for Intune when organizations standardize on Defender. If you weren’t standardized on Defender, you might leave this not configured and just rely on the generic AV requirement. Here it’s set, indicating a Defender-first strategy for antimalware.
Microsoft Defender Antimalware minimum version – 4.18.0.0. This setting specifies the lowest acceptable version of the Defender Anti-Malware client. The policy has defined 4.18.0.0 as the minimum[2]. Effect: If a device has an older Defender engine below that version, it’s noncompliant. Version 4.18.x is basically the Defender client that ships with Windows 10 and above (Defender’s engine is updated through Windows Update periodically, but the major/minor version has been 4.18 for a long time). By setting 4.18.0.0, essentially any Windows 10/11 with Defender should meet it (since 4.18 was introduced years ago). This catches only truly outdated Defender installations (perhaps if a machine had not updated its Defender platform in a very long time, or is running Windows 8.1/7, which had older Defender versions – though those OS wouldn’t be in a Win10 policy anyway). Options: Admin can input a specific version string, or leave blank (no version enforcement)[1]. The policy chose 4.18.0.0, presumably because that covers all modern Windows builds (for example, Windows 10 21H2 uses Defender engine 4.18.x). Requiring a minimum Defender version is a good practice to ensure the anti-malware engine itself isn’t outdated. Microsoft occasionally releases new engine versions with improved capabilities; if a machine somehow fell way behind (e.g., an offline machine that missed engine updates), it could have known issues or be missing detection techniques. By enforcing a minimum, you compel those devices to update their Defender platform. Version 4.18.0.0 is effectively the baseline for Windows 10, so this is a reasonable choice. It’s likely every device will already have a later version (like 4.18.210 or similar). As a best practice, some organizations might set this to an even more recent build number if they want to ensure a certain monthly platform update is installed. In any case, including this setting in the policy shows thoroughness – it’s making sure Defender isn’t an old build. This contributes to security by catching devices that might have the Defender service but not the latest engine improvements. Since the policy’s value is low (4.18.0.0), practically all supported Windows 10/11 devices comply, but it sets a floor that excludes any unsupported OS or really old install. This aligns with best practice: keep security software up-to-date, both signatures and the engine. (The admin should update this minimum version over time if needed – e.g., if Microsoft releases Defender 4.19 or 5.x in the future, they might raise the bar.)
Microsoft Defender security intelligence up-to-date – Require. This is basically ensuring Defender’s virus definitions (security intelligence) are current (Security intelligence up-to-date: Yes)[1]. If Defender’s definitions are out of date, Intune will mark noncompliant. “Up-to-date” typically means the signature is not older than a certain threshold (usually a few days, defined by Windows Security Center’s criteria). Options: Not configured (don’t check definitions currency) or Require (must have latest definitions)[1]. It’s set to Require in our policy[2]. This is clearly a best practice – an antivirus is only as good as its latest definitions. Ensuring that the AV has the latest threat intelligence is critical. This setting will catch devices that, for instance, haven’t gone online in a while or are failing to update Defender signatures. Those devices would be at risk from newer malware until they update. By marking them noncompliant, it forces an admin/user to take action (e.g. connect to the internet to get updates)[1]. This contributes directly to security, keeping anti-malware defenses sharp. It aligns with common security guidelines that AV should be kept current. Since Windows usually updates Defender signatures daily (or more), this compliance rule likely treats a device as noncompliant if signatures are older than ~3 days (Security Center flag). This policy absolutely should have this on, and it does – another check in the box for strong security practice.
Real-time protection – Require. This ensures that Defender’s real-time protection is enabled (Realtime protection: Require)[1]. Real-time protection means the antivirus actively scans files and processes as they are accessed, rather than only running periodic scans. If a user had manually turned off real-time protection (which Windows allows for troubleshooting, or sometimes malware tries to disable it), this compliance rule would flag the device. Options: Not configured or Require[1]. Our policy requires it[2]. This is a crucial setting: real-time protection is a must for proactive malware defense. Without it, viruses or spyware could execute without immediate detection, and you’d only catch them on the next scan (if at all). Best practice is to never leave real-time protection off except perhaps briefly to install certain software, and even then, compliance would catch that and mark the device not compliant with policy. So turning this on is definitely part of a strong security posture. The policy correctly enforces it. It matches Microsoft’s baseline and any sane security policy – you want continuous scanning for threats in real time. The Intune CSP for this ensures that the toggle in Windows Security (“Real-time protection”) stays on[1]. Even if a user is local admin, turning it off will flip the device to noncompliant (and possibly trigger Conditional Access to cut off corporate resource access), strongly incentivizing them not to do that. Good move.
In summary, the Defender-specific settings in this policy double-down on malware protection:
The Defender AV engine must be active (and presumably they expect to use Defender on all devices)[1].
Defender must stay updated – both engine version and malware definitions[1][1].
These are all clearly best practices for endpoint security. They ensure the built-in Windows security is fully utilized. The overlap with the general “Antivirus/Antenna” checks means there’s comprehensive coverage. Essentially, if a device doesn’t have Defender, the general AV required check would catch it; if it does have Defender, these specific settings enforce its quality and operation. No device should be running with outdated or disabled Defender in a secure environment, and this compliance policy guarantees that.
(If an organization did use a third-party AV instead of Defender, they might not use these Defender-specific settings. The presence of these in the JSON indicates alignment with using Microsoft Defender as the standard. That is indeed a good practice nowadays, as Defender has top-tier ratings and seamless integration. Many “best practice” guides, including government blueprints, now assume Defender is the AV to use, due to its strong performance and integration with Defender for Endpoint.)
Microsoft Defender for Endpoint (MDE) – Device Threat Risk Level
Finally, the policy integrates with Microsoft Defender for Endpoint (MDE) by using the setting:
Require the device to be at or under the machine risk score – Medium. This ties into MDE’s threat intelligence, which assesses each managed device’s risk level (based on detected threats on that endpoint). The compliance policy is requiring that a device’s risk level be Medium or lower to be considered compliant[1]. If MDE flags a device as High risk, Intune will mark it noncompliant and can trigger protections (like Conditional Access blocking that device). Options: Not configured (don’t use MDE risk in compliance) or one of Clear, Low, Medium, High as the maximum allowed threat level[1]. The chosen value “Medium” means: any device with a threat rated High is noncompliant, while devices with Low or Medium threats are still compliant[1]. (Clear would be the most strict – requiring absolutely no threats; High would be least strict – tolerating even high threats)[1].
Setting this to Medium is a somewhat balanced security stance. Let’s interpret it: MDE categorizes threats on devices (malware, suspicious activity) into risk levels. By allowing up to Medium, the policy is saying if a device has only low or medium-level threats, we still consider it compliant; but if it has any high-level threat, that’s unacceptable. High usually indicates serious malware outbreaks or multiple alerts, whereas low may indicate minimal or contained threats. From a security best-practice perspective, using MDE’s risk as a compliance criterion is definitely recommended – it adds an active threat-aware dimension to compliance. The choice of Medium as the cutoff is probably to avoid overly frequent lockouts for minor issues, while still reacting to major incidents.
Many security experts would advocate for even stricter: e.g. require Low or Clear (meaning even medium threats would cause noncompliance), especially in highly secure environments where any malware is concerning. In fact, Microsoft’s documentation notes “Clear is the most secure, as the device can’t have any threats”[1]. Medium is a reasonable compromise – it will catch machines with serious infections but not penalize ones that had a low-severity event that might have already been remediated. For example, if a single low-level adware was detected and quarantined, risk might be low and the device remains compliant; but if ransomware or multiple high-severity alerts are active, risk goes high and the device is blocked until cleaned[1].
In our policy JSON, it’s set to Medium[2], which is in line with many best practice guides (some Microsoft baseline recommendations also use Medium as the default, to balance security and usability). This is still considered a strong security practice because any device under an active high threat will immediately be barred. It leverages real-time threat intelligence from Defender for Endpoint to enhance compliance beyond just configuration. That means even if a device meets all the config settings above, it could still be blocked if it’s actively compromised – which is exactly what we want. It’s an important part of a Zero Trust approach: continuously monitor device health and risk, not just initial compliance.
One could tighten this to Low for maximum security (meaning even medium threats cause noncompliance). If an organization has low tolerance for any malware, they might do that. However, Medium is often chosen to avoid too many disruptions. For our evaluation: The inclusion of this setting at all is a best practice (many might forget to use it). The threshold of Medium is acceptable for strong security, catching big problems while allowing IT some leeway to investigate mediums without immediate lockout. And importantly, if set to Medium, only devices with severe threats (like active malware not neutralized) will be cut off, which likely correlates with devices that indeed should be isolated until fixed.
To summarize, the Defender for Endpoint integration means this compliance policy isn’t just checking the device’s configuration, but also its security posture in real-time. This is a modern best practice: compliance isn’t static. The policy ensures that if a device is under attack or compromised (per MDE signals), it will lose its compliant status and thus can be auto-remediated or blocked from sensitive resources[1]. This greatly strengthens the security model. Medium risk tolerance is a balanced choice – it’s not the absolute strictest, but it is still a solid security stance and likely appropriate to avoid false positives blocking users unnecessarily.
(Note: Organizations must have Microsoft Defender for Endpoint properly set up and the devices onboarded for this to work. Given it’s in the policy, we assume that’s the case, which is itself a security best practice – having EDR (Endpoint Detection & Response) on all endpoints.)
Actions for Noncompliance and Additional Considerations
The JSON policy likely includes Actions for noncompliance (the blueprint shows an action “Mark device noncompliant (1)” meaning immediate)[2]. By default, Intune always marks a device as noncompliant if it fails a setting – which is what triggers Conditional Access or other responses. The policy can also be configured to send email notifications, or after X days perform device retire/wipe, etc. The snippet indicates the default action to mark noncompliant is at day 1 (immediately)[2]. This is standard and aligns with security best practice – you want noncompliant devices to be marked as such right away. Additional actions (like notifying user, or disabling the device) could be considered but are not listed.
It’s worth noting a few maintenance and dependency points:
Updating the Policy: As new Windows versions release, the admin should review the Minimum OS version field and advance it when appropriate (for example, when Windows 10 21H1 becomes too old, they might raise the minimum to 21H2 or Windows 11). Similarly, the Defender minimum version can be updated over time. Best practice is to review compliance policies at least annually (or along with major new OS updates)[1][1] to keep them effective.
Device Support: Some settings have hardware prerequisites (TPM, Secure Boot, etc.). In a strong security posture, devices that don’t meet these (older hardware) should ideally be phased out. This policy enforces that by design. If an organization still has a few legacy devices without TPM, they might temporarily drop the TPM requirement or grant an exception group – but from a pure security standpoint, it’s better to upgrade those devices.
User Impact and Change Management: Enforcing these settings can pose adoption challenges. For example, requiring a 14-character complex password might generate more IT support queries or user friction initially. It is best practice to accompany such policy with user education and perhaps rollout in stages. The policy as given is quite strict, so ensuring leadership backing and possibly implementing self-service password reset (to handle expiry) would be wise. These aren’t policy settings per se, but operational best practices.
Complementary Policies: A compliance policy like this ensures baseline security configuration, but it doesn’t directly configure the settings on the device (except for password requirement which the user is prompted to set). It checks and reports compliance. To actually turn on things like BitLocker or firewall if they’re off, one uses Configuration Profiles or Endpoint Security policies in Intune. Best practice is to pair compliance policies with configuration profiles that enable the desired settings. For instance, enabling BitLocker via an Endpoint Security policy and then compliance verifies it’s on. The question focuses on compliance policy, so our scope is those checks, but it’s assumed the organization will also deploy policies to turn on BitLocker, firewall, Defender, etc., making it easy for devices to become compliant.
Protected Characteristics: Every setting here targets technical security and does not discriminate or involve user personal data, so no concerns there. From a privacy perspective, the compliance data is standard device security posture info.
Conclusion
Overall, each setting in this Windows compliance policy aligns with best practices for securing Windows 10/11 devices. The policy requires strong encryption, up-to-date and secure OS versions, robust password/PIN policies, active firewall and anti-malware, and even ties into advanced threat detection (Defender for Endpoint)[2][2]. These controls collectively harden the devices against unauthorized access, data loss, malware infections, and unpatched vulnerabilities.
Almost all configurations are set to their most secure option (e.g., requiring vs not, or maximum complexity) as one would expect in a high-security baseline:
Data protection is ensured by BitLocker encryption on disk[1].
Boot integrity is assured via Secure Boot and Code Integrity[1].
Users must adhere to a strict password policy (complex, long, regularly changed)[1].
Critical security features (firewall, AV, antispyware, TPM) must be in place[1][1].
Endpoint Defender is kept running in real-time and up-to-date[1].
Devices under serious threat are quarantined via noncompliance[1].
All these are considered best practices by standards such as the CIS Benchmark for Windows and government cybersecurity guidelines (for example, the ASD Essential Eight in Australia, which this policy closely mirrors, calls for application control, patching, and admin privilege restriction – many of which this policy supports by ensuring fundamental security hygiene on devices).
Are there any settings that might not align with best practice? Perhaps the only debatable one is the 365-day password expiration – modern NIST guidelines suggest you don’t force changes on a schedule unless needed. However, many organizations still view an annual password change as reasonable policy in a defense-in-depth approach. It’s a mild requirement and not draconian, so it doesn’t significantly detract from security; if anything, it adds a periodic refresh which can be seen as positive (with the understanding that user education is needed to avoid predictable changes). Thus, we wouldn’t call it a wrong practice – it’s an accepted practice in many “strong security” environments, even if some experts might opt not to expire passwords arbitrarily. Everything else is straightforwardly as per best practice or even exceeding typical baseline requirements (e.g., 14 char min is quite strong).
Improvements or additions: The policy as given is already thorough. An organization could consider tightening the Defender for Endpoint risk level to Low (meaning only absolutely clean devices are compliant) if they wanted to be extra careful – but that could increase operational noise if minor issues trigger noncompliance too often[1]. They could also reduce the idle timeout to, say, 5 or 10 minutes for devices in very sensitive environments (15 minutes is standard, though stricter is always an option). Another possible addition: enabling Jailbreak detection – not applicable for Windows (it’s more for mobile OS), Windows doesn’t have a jailbreak setting beyond what we covered (DHA covers some integrity). Everything major in Windows compliance is covered here.
One more setting outside of this device policy that’s a tenant-wide setting is “Mark devices with no compliance policy as noncompliant”, which we would assume is enabled at the Intune tenant level for strong security (so that any device that somehow doesn’t get this policy is still not trusted)[3]. The question didn’t include that, but it’s a part of best practices – likely the organization would have set it to Not compliant at the tenant setting to avoid unmanaged devices slipping through[3].
In conclusion, each listed setting is configured in line with strong security best practices for Windows devices. The policy reflects an aggressive security posture: it imposes strict requirements that greatly reduce the risk of compromise. Devices that meet all these conditions will be quite well-hardened against common threats. Conversely, any device failing these checks is rightfully flagged for remediation, which helps the IT team maintain a secure fleet. This compliance policy, especially when combined with Conditional Access (to prevent noncompliant devices from accessing corporate data) and proper configuration policies (to push these settings onto devices), provides an effective enforcement of security standards across the Windows estate[3][3]. It aligns with industry guidelines and should substantially mitigate risks such as data breaches, malware incidents, and unauthorized access. Each setting plays a role: from protecting data encryption and boot process to enforcing user credentials and system health – together forming a comprehensive security baseline that is indeed consistent with best practices.
In today’s digital workspace, AI-powered assistants like Microsoft 365 Copilot and traditional search engines serve different purposes and excel in different scenarios. This guide explains why you should not treat an AI tool such as Copilot as a general web search engine, and details when to use AI over a normal search process. We also provide example Copilot prompts that outperform typical search queries in answering common questions.
Understanding AI Tools (Copilot) vs. Traditional Search Engines
AI tools like Microsoft 365 Copilot are conversational, context-aware assistants, whereas search engines are designed for broad information retrieval. Copilot is an AI-powered tool that helps with work tasks, generating responses in real-time using both internet content and your work content (emails, documents, etc.) that you have permission to access[1]. It is embedded within Microsoft 365 apps (Word, Excel, Outlook, Teams, etc.), enabling it to produce outputs relevant to what you’re working on. For example, Copilot can draft a document in Word, suggest formulas in Excel, summarize an email thread in Outlook, or recap a meeting in Teams, all by understanding the context in those applications[1]. It uses large language models (like GPT-4) combined with Microsoft Graph (your organizational data) to provide personalized assistance[1].
On the other hand, a search engine (like Google or Bing) is a software system specifically designed to search the World Wide Web for information based on keywords in a query[2]. A search engine crawls and indexes billions of web pages and, when you ask a question, it returns a list of relevant documents or links ranked by algorithms. The search engine’s goal is to help you find relevant information sources – you then read or navigate those sources to get your answer.
Key differences in how they operate:
Result Format: A traditional search engine provides you with a list of website links, snippets, or media results. You must click through to those sources to synthesize an answer. In contrast, Copilot provides a direct answer or content output (e.g. a summary, draft, or insight), often in a conversational format, without requiring you to manually open multiple documents. It can combine information from multiple sources (including your files and the web) into a single cohesive response on the spot[3].
Context and Personalization: Search engines can use your location or past behavior for minor personalization, but largely they respond the same way to anyone asking a given query. Copilot, however, is deeply personalized to your work context – it can pull data from your emails, documents, meetings, and chats via Microsoft Graph to tailor its responses[1]. For example, if you ask “Who is my manager and what is our latest project update?”, Copilot can look up your manager’s name from your Office 365 profile and retrieve the latest project info from your internal files or emails, giving a personalized answer. A public search engine would not know these personal details.
Understanding of Complex Language: Both modern search engines and AI assistants handle natural language, but Copilot (AI) can engage in a dialogue. You can ask Copilot follow-up questions or make iterative requests in a conversation, refining what you need, which is not how one interacts with a search engine. Copilot can remember context from earlier in the conversation for additional queries, as long as you stay in the same chat session or document, enabling complex multi-step interactions (e.g., first “Summarize this report,” then “Now draft an email to the team with those key points.”). A search engine treats each query independently and doesn’t carry over context from previous searches.
Learning and Adaptability:AI tools can adapt outputs based on user feedback or organization-specific training. Copilot uses advanced AI (LLMs) which can be “prompted” to adjust style or content. For instance, you can tell Copilot “rewrite this in a formal tone” or “exclude budget figures in the summary”, and it will attempt to comply. Traditional search has no such direct adaptability in generating content; it can only show different results if you refine your keywords.
Output Use Cases: Perhaps the biggest difference is in what you use them for: Copilot is aimed at productivity tasks and analysis within your workflow, while search is aimed at information lookup. If you need to compose, create, or transform content, an AI assistant shines. If you need to find where information resides on the web, a search engine is the go-to tool. The next sections will dive deeper into these distinctions, especially why Copilot is not a straight replacement for a search engine.
Limitations of Using Copilot as a Search Engine
While Copilot is powerful, you should not use it as a one-to-one substitute for a search engine. There are several reasons and limitations that explain why:
Accuracy and “Hallucinations”: AI tools sometimes generate incorrect information very confidently – a phenomenon often called hallucination. They do not simply fetch verified facts; instead, they predict answers based on patterns in training data. A recent study found that generative AI search tools were inaccurate about 60% of the time when answering factual queries, often presenting wrong information with great confidence[4]. In that evaluation, Microsoft’s Copilot (in a web search context) was about 70% completely inaccurate in responding to certain news queries[4]. In contrast, a normal search engine would have just pointed to the actual news articles. This highlights that Copilot may give an answer that sounds correct but isn’t, especially on topics outside your work context or beyond its training. Using Copilot as a general fact-finder can thus be risky without verification.
Lack of Source Transparency: When you search the web, you get a list of sources and can evaluate the credibility of each (e.g., you see it’s from an official website, a recent date, etc.). With Copilot, the answer comes fused together, and although Copilot does provide citations in certain interfaces (for instance, Copilot in Teams chat will show citations for the sources it used[1]), it’s not the same as scanning multiple different sources yourself. If you rely on Copilot alone, you might miss the nuance and multi-perspective insight that multiple search results would offer. In short, Copilot might tell you “According to the data, Project Alpha increased sales by 5%”, whereas a search engine would show you the report or news release so you can verify that 5% figure in context. Over-reliance on AI’s one-shot answer could be misleading if the answer is incomplete or taken out of context.
Real-Time Information and Knowledge Cutoff:Search engines are constantly updated – they crawl news sites, blogs, and the entire web continuously, meaning if something happened minutes ago, a search engine will likely surface it. Copilot’s AI model has a knowledge cutoff (it doesn’t automatically know information published after a certain point unless it performs a live web search on-demand). Microsoft 365 Copilot can fetch information from Bing when needed, but this is an optional feature under admin control[3][3], and Copilot has to decide to invoke it. If web search is disabled or if Copilot doesn’t recognize that it should look online, it will answer from its existing knowledge base and your internal data alone. Thus, for breaking news or very recent events, Copilot might give outdated info or no info at all, whereas a web search would be the appropriate tool. Even with web search enabled, Copilot generates a query behind the scenes and might not capture the exact detail you want, whereas you could manually refine a search engine query. In summary, Copilot is not as naturally in tune with the latest information as a dedicated search engine[5].
Breadth of Information:Copilot is bounded by what it has been trained on and what data you provide to it. It is excellent on enterprise data you have access to and general knowledge up to its training date, but it is not guaranteed to know about every obscure topic on the internet. A search engine indexes virtually the entire public web; if you need something outside of Copilot’s domain (say, a niche academic paper or a specific product review), a traditional search is more likely to find it. If you ask Copilot an off-topic question unrelated to your work or its training, it might struggle or give a generic answer. It’s not an open portal to all human knowledge in the way Google is.
Multiple Perspectives and Depth: Some research questions or decisions benefit from seeing diverse sources. For example, before making a decision you might want to read several opinions or analyses. Copilot will tend to produce a single synthesized answer or narrative. If you only use that, you could miss out on alternative viewpoints or conflicting data that a search could reveal. Search engines excel at exploratory research – scanning results can give you a quick sense of consensus or disagreement on a topic, something an AI’s singular answer won’t provide.
Interaction Style: Using Copilot is a conversation, which is powerful but can also be a limitation when you just need a quick fact with zero ambiguity. Sometimes, you might know exactly what you’re looking for (“ISO standard number for PDF/A format”, for instance). Typing that into a search engine will instantly yield the precise fact. Asking Copilot might result in a verbose answer or an attempt to be helpful beyond what you need. For quick, factoid-style queries (dates, definitions, simple facts), a search engine or a structured Q\&A database might be faster and cleaner.
Cost and Access: While not a technical limitation, it’s worth noting that Copilot (and similar AI services) often comes with licensing costs or usage limits[6]. Microsoft 365 Copilot is a premium feature for businesses or certain Microsoft 365 plans. Conducting a large number of general searches through Copilot could be inefficient cost-wise if a free search engine could do the job. In some consumer scenarios, Copilot access might even be limited (for example, personal Microsoft accounts have a capped number of Copilot uses per month without an upgrade[6]). So, from a practical standpoint, you wouldn’t want to spend your limited Copilot queries on trivial lookups that Bing or Google could handle at no cost.
Ethical and Compliance Factors: Copilot is designed to respect organizational data boundaries – it won’t show you content from your company that you don’t have permission to access[1]. On the flip side, if you try to use it like a search engine to dig up information you shouldn’t access, it won’t bypass security (which is a good thing). A search engine might find publicly available info on a topic, but Copilot won’t violate privacy or compliance settings to fetch data. Also, in an enterprise, all Copilot interactions are auditable by admins for security[3]. This means your queries are logged internally. If you were using Copilot to search the web for personal reasons, that might be visible to your organization’s IT – another reason to use a personal device or external search for non-work-related queries.
Bottom line:Generative AI tools like Copilot are not primarily fact-finding tools – they are assistants for generating and manipulating content. Use them for what they’re good at (as we’ll detail next), and use traditional search when you need authoritative information discovery, multiple source verification, or the latest updates. If you do use Copilot to get information, be prepared to double-check important facts against a reliable source.
When to Use AI Tools (Copilot) vs. When to Use Search Engines
Given the differences and limitations above, there are distinct scenarios where using an AI assistant like Copilot is advantageous, and others where a traditional search is better. Below are detailed reasons and examples for each, to guide you on which tool to use for a given need:
Scenarios Where Copilot (AI) Excels:
Synthesizing Information and Summarization: When you have a large amount of information and need a concise summary or insight, Copilot shines. For instance, if you have a lengthy internal report or a 100-thread email conversation, Copilot can instantly generate a summary of key points or decisions. This saves you from manually reading through tons of text. One of Copilot’s standout uses is summarizing content; reviewers noted the ability to condense long PDFs into bulleted highlights as “indispensable, offering a significant boost in productivity”[7]. A search engine can’t summarize your private documents – that’s a job for AI.
Using Internal and Contextual Data:If your question involves data that is internal to your organization or personal workflow, use Copilot. No search engine can index your company’s SharePoint files or your Outlook inbox (those are private). Copilot, however, can pull from these sources (with proper permissions) to answer questions. For example, *“What decision did
In this video, I walk you through my step-by-step process for creating a powerful, no-cost Microsoft 365 Copilot chat agent that searches my blog and delivers instant, well-formatted answers to technical questions. Watch as I demonstrate how to set up the agent, configure it to use your own public website as a knowledge source, and leverage AI to boost productivity—no extra licenses required! Whether you want to streamline your workflow, help your team access information faster, or just see what’s possible with Microsoft 365’s built-in AI, this guide will show you how to get started and make the most of your content. if you want a copy of the ‘How to’ document for this video then use this link – https://forms.office.com/r/fqJXdCPAtU
If you found this valuable, the I’d appreciate a ‘like’ or perhaps a donation at https://ko-fi.com/ciaops. This helps me know that people enjoy what I have created and provides resources to allow me to create more content. If you have any feedback or suggestions around this, I’m all ears. You can also find me via email director@ciaops.com and on X (Twitter) at https://www.twitter.com/directorcia.
If you want to be part of a dedicated Microsoft Cloud community with information and interactions daily, then consider becoming a CIAOPS Patron – www.ciaopspatron.com.
Here’s a detailed breakdown to help you decide when to use Microsoft 365 Copilot (standard) versus a dedicated agent like Researcher or Analyst, especially for SMB (Small and Medium Business) customers. This guidance is based on internal documentation, email discussions, and Microsoft’s public announcements.
Uses Microsoft Graph to access your tenant’s data securely.
Best for lightweight tasks and real-time assistance
Researcher Agent
Designed for deep, multi-step reasoning.
Gathers and synthesizes information from emails, files, meetings, chats, and the web.
Produces structured, evidence-backed reports with citations.
Ideal for market research, competitive analysis, go-to-market strategies, and client briefings.
Analyst Agent
Thinks like a data scientist.
Uses chain-of-thought reasoning and can run Python code.
Ideal for data-heavy tasks: forecasting, customer segmentation, financial modeling.
Can analyze data across multiple spreadsheets and visualize insights.
SMB-Specific Considerations
Licensing: SMBs using Microsoft 365 Business Premium can access Copilot, but Researcher and Analyst require Copilot licenses and are part of the Frontier program.
Security: Business Premium includes tools like eDiscovery, audit logging, and data loss prevention to monitor Copilot usage and protect sensitive data.
Deployment: SMBs should ensure foundational productivity setup, data structuring, and AI readiness before deploying advanced agents.
Simple Guidance for SMBs
Start with M365 Copilot Chat for daily tasks, onboarding, and quick answers.
Use Researcher when you need a comprehensive answer that spans multiple data sources and includes citations.
Use Analyst when you need to analyze or visualize data, especially for strategic planning or reporting.
To deploy Microsoft 365 Copilot, including the Researcher and Analyst agents, in small and medium-sized businesses (SMBs), you’ll need to follow a structured approach that balances licensing, governance, security, and user enablement. Here’s a detailed breakdown based on internal documentation, email guidance, and Microsoft’s official resources.
Deployment Overview for SMBs
1. Licensing Requirements
To use Microsoft 365 Copilot and its advanced agents:
Base License: Users must have one of the following:
Microsoft 365 Business Premium
Microsoft 365 E3 or E5
Office 365 E3 or E5
Copilot Add-on License: Required for access to tenant data and advanced agents like Researcher and Analyst. This license costs approximately \$360/year per user.
2. Agent Availability and Installation
Microsoft provides three deployment paths for agents:
Agent Type
Who Installs
Examples
Governance
Microsoft-installed
Microsoft
Researcher, Analyst
Admins can block globally
Admin-installed
IT Admins
Custom or partner agents
Full lifecycle control
User-installed
End users
Copilot Studio agents
Controlled by admin policy
Researcher and Analyst are pre-installed and pinned for all users with Copilot licenses.
Admins can manage visibility and access via the Copilot Control System in the Microsoft 365 Admin Center.
3. Security and Governance for SMBs
Deploying Copilot in SMBs requires attention to data access and permission hygiene:
Copilot respects existing permissions, but if users are over-permissioned, they may inadvertently access sensitive data.
Use least privilege access principles to avoid data oversharing.
Leverage Microsoft 365 Business Premium features like:
Microsoft Purview for auditing and DLP
Entra ID for Conditional Access
Defender for Business for endpoint protection
4. Agent Creation with Copilot Studio
For SMBs wanting tailored AI experiences:
Use Copilot Studio to build custom agents for HR, IT, or operations.
No-code interface allows business users to create agents without developer support.
Agents can be deployed in Teams, Outlook, or Copilot Chat for seamless access.
5. Training and Enablement
Encourage users to explore agents via the Copilot Chat web tab.
Use Copilot Academy and Microsoft’s curated learning paths to upskill staff.
Promote internal champions to guide adoption and gather feedback.
✅ Deployment Checklist for SMBs
Step
Action
1
Confirm eligible Microsoft 365 licenses
2
Purchase and assign Copilot licenses
3
Review and tighten user permissions
4
Enable or restrict agents via Copilot Control System
Managing Microsoft 365 (M365) issues on behalf of customers is a core responsibility for Small-to-Medium Business Managed Service Providers (SMB MSPs). A structured approach to working with Microsoft Support can significantly speed up issue resolution and ensure a seamless support experience for both the MSP and the customer. This guide outlines a step-by-step process for engaging Microsoft Support effectively, along with best practices to maintain clear communications and minimize downtime. We’ll cover initial troubleshooting, opening and managing support tickets, communication strategies, and post-resolution follow-ups – all tailored to help an MSP navigate Microsoft’s support system efficiently while keeping customers informed.
Step 1: Initial Issue Assessment and Troubleshooting
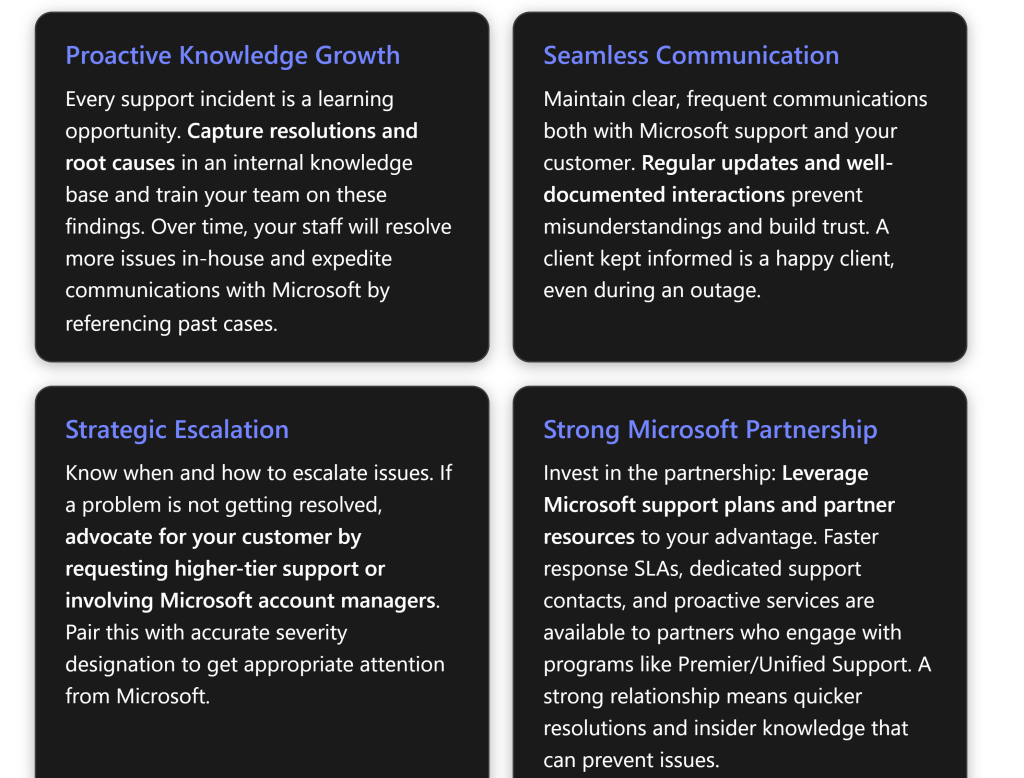
Begin with a thorough internal assessment of the problem. As soon as an issue is reported by the customer, the MSP should gather key details and attempt basic troubleshooting. Start by identifying what is not working and who is affected. For example, determine if the issue is isolated to a single user or widespread, and note any error messages or abnormal behaviors observed[1]. It’s important to replicate the problem if possible, to confirm its scope and symptoms. Documenting the exact steps that lead to the error will help both your team and Microsoft pinpoint the cause[1].
Next, perform common initial fixes and checks. Depending on the nature of the issue, this might include actions such as: clearing browser cache and cookies (for web app issues), trying an alternative browser, restarting the affected application or device, checking the user’s account status and permissions, and verifying internet connectivity[1]. For Outlook or desktop Office app problems, one might attempt steps like creating a new mail profile or ensuring the latest updates are installed[1]. These standard troubleshooting steps often resolve transient issues or reveal configuration problems without needing to contact Microsoft.
Meanwhile, check the Microsoft 365 Service Health Dashboard in the tenant’s admin center to see if any known outages or incidents could be related. Microsoft might already be aware of a problem affecting multiple customers; if so, the dashboard or Message Center will have alerts. If a relevant service incident is listed (e.g. “Exchange Online – Users may be unable to send emails”), this can save time by confirming the issue is on Microsoft’s side. In such cases, your role may shift to monitoring Microsoft’s updates and keeping the customer informed, rather than troubleshooting something that is out of your control.
If the issue appears to be specific to the customer’s environment, gather diagnostic data early. For example, note the exact time the issue occurred (important for log correlation)[1], and whether it is continuous or intermittent. Identify any changes in the environment that happened around the onset of the issue – for instance, was a new update applied, or was a configuration changed? Having this context will be valuable information. The initial assessment should result in a clear problem statement (what is happening, under what conditions, and impact), along with a list of steps already taken to troubleshoot.
By thoroughly completing this Step 1, the MSP can either resolve simple issues independently or, for more complex problems, be well-prepared to engage Microsoft with a solid understanding of the situation.
Step 2: Utilize Self-Help Resources and Tools
Before escalating to Microsoft Support, leverage the abundant self-help resources and automated tools available for M365. Microsoft provides extensive documentation and diagnostic utilities that MSPs can use to either fix the issue or collect additional information. Utilizing these resources can often lead to a quick solution and demonstrates due diligence when you do need to involve Microsoft.
Search Microsoft’s Knowledge Base and Community Forums: Microsoft’s official support site and Tech Community forums contain a wealth of articles and Q\&A threads on common M365 issues. It’s often helpful to search for the specific error codes or symptoms you’ve observed. This could surface known fixes or user-contributed solutions. For example, if a SharePoint site isn’t loading for a client, a quick search might reveal an ongoing issue or a configuration tweak that solves it. Microsoft’s documentation and the community can save time by pointing to existing solutions for known problems, so you’re not “reinventing the wheel.”
Run Microsoft 365 Troubleshooters: Microsoft offers automated troubleshooters in the “Get Help” app for many Office 365 applications[2]. These wizards can detect and often fix issues related to Outlook email configuration, Office activation, Teams connectivity, etc. For instance, the Microsoft 365 Support and Recovery Assistant (SaRA) is a downloadable tool that can diagnose problems with Outlook profiles, connectivity to Exchange Online, or OneDrive sync issues. Running these tools on the affected system can either fix the issue automatically or gather detailed logs and error reports that will be useful if you escalate to Microsoft[3][3]. Ensure you note any errors or results from these utilities to include in your case notes.
Use the Remote Connectivity Analyzer and Other Diagnostic Tools: For issues like Exchange mail flow, Skype for Business/Teams connectivity, or network-related problems, Microsoft’s Remote Connectivity Analyzer (available online) can perform tests from outside the environment to identify DNS misconfigurations or firewall issues[3]. Tools like Message Trace in the Exchange admin center, or SharePoint’s built-in health checks, are also valuable to run beforehand. If an email is not being delivered, a message trace might show it never left the outbound queue, indicating the problem lies before Microsoft ever needs to step in.
Performing these self-help steps serves two purposes: you might resolve the issue without needing formal Microsoft support, and if not, you will have richer information to provide to Microsoft. Microsoft’s support engineers often ask for these very diagnostics early in the support process. By doing them upfront, you can include the results in your initial ticket submission, potentially avoiding one or two back-and-forth cycles with support[4][4]. For example, instead of Microsoft asking you to run a network test after you open the case, you can preempt that request by saying “We ran the Microsoft 365 network connectivity test – see attached results showing high latency to the Exchange Online service endpoint.” This proactive approach shows Microsoft that the MSP has taken initiative and can accelerate the troubleshooting phase.
In summary, exhaust the readily available troubleshooting avenues. This will either fix the problem promptly or arm you with data and confirmation of what the issue is not, which is equally helpful. Once you have done this homework and the issue still persists, it’s time to engage Microsoft Support with confidence that you’ve covered the basics.
Step 3: Prepare Detailed Case Documentation for Microsoft
If the issue requires Microsoft’s assistance, preparation is critical before you actually create a support ticket. A well-documented case description can drastically reduce resolution time by enabling Microsoft engineers to understand the problem context immediately. Gather and organize all relevant information about the issue so that you can provide Microsoft a comprehensive picture from the outset.
Key information to collect includes:
In practice, creating a short document or ticket draft with all these points is helpful. Below is a checklist of information you should have ready (and ideally include in the support request description or attachments):
Checklist: Information to Include in a Microsoft Support Case
Information to Gather Description / Example
Issue Summary A one-sentence description of the problem and its effect. E.g., “Users receive error ‘Cannot connect to mailbox’ when launching Outlook, unable to send/receive email.”
Error Messages or Codes The exact wording of any error and any error code displayed. Include screenshots if applicable[1][1]. E.g., Error 0x8004010F in Outlook.
Affected Users/Services Who or what is impacted. E.g., “One user (user@company.com)” or “All users in tenant” or “SharePoint site X.” This helps scope the issue[1].
Date/Time and Frequency When the issue started and how often it occurs. E.g., “Started around 3:00 PM UTC on July 10, happens every time user tries to login”[1].
Steps to Reproduce Step-by-step actions that consistently trigger the problem[1]. E.g., “Open Teams, click Calendar, error pops up.” If not consistent, describe conditions when it occurs.
Troubleshooting Performed List of actions already taken to diagnose or fix the issue[1]. E.g., “Rebooted PC, cleared app cache, tried on different network, issue persists.”
Environment Details Relevant technical context: operating system and version, Office app version, browser version, device type, etc.[1]. E.g., “Windows 11 + Office 365 Apps v2306, on domain-joined PC.”
Recent Changes Any notable changes prior to onset. E.g., “Exchange license was modified this morning” or “Windows update applied last night.”
Business Impact Briefly explain the severity from the customer’s perspective. E.g., “Executive assistant cannot access mailbox to schedule meetings, causing delays.”
Including screenshots or logs as attachments is highly recommended, especially if the issue is complex. For instance, if SharePoint is showing an error, take a screenshot of the error page. If email is not flowing, perhaps attach the non-delivery report (NDR) or relevant log excerpt. Ensure any sensitive information is handled appropriately (Microsoft support has mechanisms for secure file upload if needed). As a security measure, Microsoft may require you to consent to them accessing diagnostic information or logs from the tenant[5]; be prepared to grant that in the admin portal when opening the case.
This level of detailed documentation achieves two things: (1) it provides Microsoft the information needed to start troubleshooting immediately, and (2) it demonstrates that the MSP has been methodical, which can instill confidence and lead to more efficient collaboration. When you clearly communicate what you’ve observed and done, Microsoft support can skip asking basic questions and move straight to advanced diagnostics or known issue checks. According to internal guidelines, help desk agents appreciate when you “provide as much detail as possible… all symptoms, error messages, exact steps to reproduce, and any troubleshooting already completed”[1][1] up front.
Take a moment to review and organize this info before submitting it. Now you’re ready to create a well-informed support ticket.
Step 4: Create a Microsoft Support Ticket (Service Request)
With all the necessary information at hand, the next step is to open a support case with Microsoft through the appropriate channel. For M365 issues, this is typically done via the Microsoft 365 Admin Center for the customer’s tenant (or via your Partner Center if you are a Cloud Solution Provider managing on behalf of the client). The process is straightforward but there are a few things to do carefully to optimize the support experience.
Access the Support Interface: Log in to the Microsoft 365 Admin Center with an administrator account that has permissions to create support requests (Global Admin or a delegated admin role for partners)[6]. In the left navigation menu, click on “Support” (or the question mark icon), then choose “New service request” or “Get help”. This will initiate the case creation flow[6].
Fill in the Issue Details: You will be prompted to describe the problem. Provide a concise yet specific description in the summary or subject line, and paste in the detailed description you prepared (from Step 3) into the description field[6]. Focus on the key facts: what the issue is, when it started, who is affected, and what error is seen[6]. There may be dropdowns to categorize the issue (e.g., select “Exchange Online” or “Microsoft Teams” depending on the service). Choose the category that best fits so the ticket is routed to the right support team.
Most support forms allow attachments; attach your screenshots, error logs, or any files that can help illustrate the problem[6]. Also, if the form supports it, include the steps already taken and the business impact in the description. Essentially, you want the support engineer who picks up the ticket to see all the relevant information immediately upon reading your case.
Set the Severity (Priority) Level: Microsoft will ask you to indicate how severe/urgent the issue is. Choose the appropriate priority based on the business impact – do not understate it, but also be accurate and avoid inflating for a minor issue. Typically, the levels are something like[6]:
Critical (Severity A) – Severe business impact, e.g., entire service down or all users unable to work. (Use sparingly, reserved for major outages)[6].
High – Significant impact, but operations partially functioning, e.g., multiple users or a major feature is affected.
Medium – Moderate impact, e.g., issue affects one or a few users or has a workaround available.
Low – Non-urgent or consultative issues, general questions.
Selecting the right severity is important because it influences response times and resource allocation. For instance, a Critical incident may trigger immediate attention (in Premier Support cases, a 15-minute response is expected for Sev 1[7], whereas in standard support a Sev A might be around 1-hour initial response). Keep in mind that if you mark something Critical, Microsoft expects you to be actively available to work with them in real-time until resolution, as these are 24/7 engagement scenarios. Conversely, mislabeling a low-impact issue as Critical could strain credibility or lead to unnecessary urgency.
Review and Submit: Before hitting submit, double-check everything[6]. Ensure contact information (your email/phone) is correct. Verify that your description is clear and attachments are properly uploaded. It’s easy to overlook details in the rush, but spending an extra minute here can prevent miscommunication later. Once satisfied, submit the ticket. The system will generate a case number (write this down!) and you should receive an email confirmation with the case reference[6].
Immediately after submission, if the issue is very urgent (e.g., a production outage), consider also calling Microsoft support by phone and referencing your case number. For Microsoft 365, phone support is available for admins – the confirmation email or support portal will list a number for critical issues. By calling in and giving the case number, you can sometimes expedite the assignment of an engineer, especially off-hours.
In summary, treat the support ticket creation like crafting a medical chart for a doctor – clear symptoms, history, and severity. A well-crafted ticket with the right priority set will go to the correct support queue and person with minimal delay, setting the stage for a faster resolution[8]. Now that the case is open, the collaborative phase with Microsoft support begins.
Step 5: Engage and Communicate Effectively with Microsoft Support
Once your support case is logged, an engineer from Microsoft (or a support agent from the initial triage team) will be assigned to work with you. Effective communication with the support engineer is crucial for a smooth resolution. As an MSP acting on behalf of your customer, you are the liaison between Microsoft and the client’s issue, so managing this communication well will ensure nothing falls through the cracks.
Respond Promptly and Professionally: Microsoft may reach out via the case portal, email, or phone – often depending on severity and time of day. Aim to respond to any queries or requests for information as quickly as possible. The faster you answer their questions or perform requested tests, the faster the issue can progress. Keep your responses clear and concise, addressing all points the support engineer asked. For example, if they ask for a specific log file or to run a PowerShell command, do that promptly and report the results or upload the logs. Document each action and result in your reply so it’s easy for the engineer to follow[6].
Maintain Clarity and Completeness: When communicating with the support engineer, remember they might not be familiar with your environment beyond what you provided. Be explicit in your descriptions. Avoid acronyms or internal jargon that Microsoft might not know – use standard terminology. It can help to structure your communications in bullet points or numbered steps if you have multiple things to convey (much like how we prepared the case information). If sending an email update, for instance, recap: “We have tried X and Y as suggested, here are the outcomes… We are also seeing new error code __ at 10:15 AM. Attached are the latest logs.” This level of clarity ensures the engineer doesn’t miss important details. Microsoft’s own best practice guidelines suggest using clear, straightforward language and providing as much detail as possible in each communication[6].
Cooperate with Diagnostic Requests: It’s common for Microsoft support to request additional diagnostics – e.g., enabling logging, collecting trace files, or trying a specialized troubleshooting step. Even if you performed similar steps earlier, follow their guidance; they might want data captured in a specific way or format. For example, they may send you a link to run a Microsoft Support Diagnostic Package (which could collect detailed telemetry from your tenant with your approval). Work with the customer’s environment to run these and promptly share the results. Each iteration of data collection can take time, so the sooner you fulfill these requests, the better. When providing files or logs, double-check you are not omitting anything, which could lead to another round-trip (e.g., “Oops, you sent the wrong log file, can you send this other one too?”).
Keep a Log of Interactions: As an MSP, it’s wise to maintain an internal log of everything that happens on the case – basically your own running notes separate from the Microsoft case portal. Log timestamps of communications, the name of the Microsoft engineer(s) you speak with, and summary of discussions[6]. Note any case escalations or commitments (e.g., “Microsoft will get back to us by 5 PM with an update.”). This not only helps in case you need to brief someone else on your team or the customer, but also is useful if the case needs to be handed over to a different Microsoft engineer – you can quickly get them up to speed on what’s been done.
Importantly, ensure consistency and persistence. If the issue is ongoing, try to have one point of contact from your MSP (perhaps you or a designated engineer) handle communications with Microsoft, to avoid confusion. That person should stay engaged until resolution. Should you need to bring in another colleague (for example, a specialist on a technology), coordinate so Microsoft gets clear answers and doesn’t hear different information from multiple sources.
Escalation within Microsoft Support: If you sense that the support engineer is not grasping the problem or progress is stalled, you can politely request an escalation. Microsoft has tiers of support; the first engineer might be a generalist doing initial troubleshooting. If after a reasonable back-and-forth the issue remains unsolved, you can say: “This issue is impacting our customer significantly. Could we involve a senior engineer or a specialist for deeper analysis?” Many seasoned MSPs find that asking for a higher-tier engineer or a product expert can break a deadlock[4]. Microsoft’s own forums note that you can “specify in the ticket that you want an expert and not a level 1 support” for complex issues[4] – this can sometimes connect you with someone with deeper knowledge sooner. Of course, use this judiciously and always remain courteous; the front-line support is there to help, and showing collaboration (not frustration) often encourages them to champion your case internally.
Leverage Real-Time Communication if Available: Sometimes email or the portal isn’t enough, especially for complex issues. Don’t hesitate to schedule a call or Teams session with the support engineer. Interactive troubleshooting can resolve things faster since you can share screens, demonstrate the issue live, or perform actions while the engineer observes. In critical cases, Microsoft might initiate a conference call or even a remote session (with your permission) to solve the problem. Be ready to allocate time for these live sessions as they can be the quickest path to a fix for thorny problems.
Throughout engagement, maintain a professional and solution-focused tone. It’s understandable to be under pressure from your customer, but refrain from letting frustration seep into communications with Microsoft. If the process is dragging, you can firmly but politely highlight the urgency and impact to encourage swift action[4]. Microsoft’s support personnel generally want to help you; establishing a cooperative rapport will make them more likely to go the extra mile. Remember, you and Microsoft are essentially on the same team with the shared goal of resolving the customer’s issue.
By communicating effectively at this step – being responsive, clear, and collaborative – you increase the likelihood of Microsoft Support diagnosing the issue correctly and providing a resolution in the shortest possible time.
Step 6: Track Case Progress and Escalate if Necessary
While Microsoft is working on the issue, it’s important for the MSP to actively manage and monitor the support case. Do not assume that once the ticket is logged, you can sit back and wait indefinitely. Staying on top of the case progress, and knowing when to push for escalation, is key to ensuring the issue gets resolved in a timely manner.
Monitor Updates in the Portal: The Microsoft 365 Admin Center (or Partner Center) will show the status of your support requests. Check the case status regularly in the “View my requests” section[6]. Microsoft engineers often add notes or ask questions in the portal’s case log. Ensure you have notifications enabled (you should get an email when they update the case, but it’s good practice to manually check as well, especially if the issue is critical). Timely reading and responding to these updates keeps things moving. If Microsoft marked the case as “Solution Provided” or “Pending Customer,” be sure to review what they’ve given – sometimes they might post a potential fix and wait for you to test and confirm.
Keep the Customer Ticket Updated: In your internal MSP ticketing system, continue to log each development (this was touched on in Step 5 as well). Label the ticket status clearly – for example, “Waiting on Microsoft” is a common status to indicate the ball is in Microsoft’s court[9]. This way, if colleagues or managers look at the ticket, they know it’s been escalated externally. Document any interim solution applied or any promises of follow-up from Microsoft (e.g., “Microsoft will provide an update within 24 hours after their internal team analysis”). This internal documentation discipline ensures nothing is forgotten and is useful for post-incident review.
Follow Up Regularly: If you haven’t heard back within the timeframe you expected, don’t hesitate to follow up with Microsoft[6]. As a guideline, if a day passes with no update on a non-critical issue, it’s reasonable to send a friendly inquiry: “Just checking if there are any updates or if any further information is needed from our side.” For higher priority cases, follow up even sooner (e.g., every few hours for a critical outage). Support queues can be busy, so a gentle reminder can refocus attention on your case. Be sure to reference your case number in any communication to avoid confusion.
Recognize When to Escalate: Sometimes an issue might be stuck without progress – perhaps the support engineer is waiting on input from a back-end product team, or they haven’t identified the root cause yet. If your issue has been open for an extended period with little traction, or if the impact on the customer is escalating, it may be time to escalate the case to a higher support tier or to management. Microsoft has an escalation process; you can ask the current support engineer to “please escalate this case, as the situation is urgent and we’re not seeing progress.” Many MSPs have learned that persistent follow-up calls can prompt escalation – one admin described calling every day and asking for escalation until the case moved up to tier 3 and eventually an engineer who could reproduce the issue was assigned[4]. While hopefully not every case requires such aggressive follow-up, know that escalation is an option in your toolbox.
If you are a Microsoft partner with Premier/Unified Support or Advanced Support for Partners, you might also have an assigned Technical Account Manager (TAM) or service lead whom you can reach out to for escalation assistance. They can often pull strings internally to get more resources on a critical case. If not, escalating through the normal support line is fine – ask for a supervisor if needed, explaining the business impact.
Adjust Severity if the Impact Worsens: The initial severity you set (Step 4) might need to be updated if things change. For instance, you opened as “High” priority because it affected a few users, but now it’s affecting the entire company. Communicate this change to Microsoft and request the case be treated with higher severity. They may need to formally update the ticket classification on their end to get the appropriate attention. Conversely, if a workaround has mitigated the immediate pain, you might downgrade the urgency when speaking with support (though usually leaving the severity as-is until final resolution is fine).
Throughout this process, keep the customer informed (which we’ll address in the next section in detail). They should know that the case is in progress and that you’re actively managing it. It can be very reassuring for a client to hear, “We have a Microsoft support case open and we’re checking in with them regularly; we’ve also requested an escalation due to the importance of this issue.”
Finally, know the escalation path on your side as well. If you’re the frontline MSP engineer and things are not moving, loop in your own management or a senior engineer for advice. Maybe someone in your company has seen a similar issue before, or has a partner channel contact at Microsoft. As an MSP, it’s about leveraging all resources to advocate for your customer’s needs.
In summary, treat support cases as active projects that need management. Regular attention and timely escalation can shave days off the resolution time, minimizing the disruption for your customer[10]. Persistence (with politeness) is often necessary to ensure your case doesn’t get lost in the shuffle.
Step 7: Update the Customer and Manage Expectations
Parallel to the technical troubleshooting, client communication is a continuous thread that must be maintained. Your customer is likely anxious to have their problem resolved, and part of your role as their MSP is to keep them informed and confident that progress is being made. Effective communication with the customer ensures a seamless support experience, even if the issue itself is complex or lengthy to resolve.
Initial Notification to the Customer: As soon as you recognize the issue and have engaged Microsoft (or even before that, during initial troubleshooting if it’s obvious the problem is significant), let the customer know you are aware of the problem and taking action. Acknowledge the issue in clear terms – for example, “We’re aware that several users cannot access email and we have identified this as a likely server-side issue. We’ve engaged Microsoft support to assist.” According to MSP outage communication best practices, an immediate alert should include a brief description of the problem, who/what is impacted, and steps being taken[11]. This early communication reassures the client that their MSP is on top of things and prevents them from feeling the need to chase for updates.
Set Expectations on Timeline: In your initial or early communications, it’s important to manage expectations. If you’ve opened a Microsoft case, you might say, “Microsoft support is now investigating; based on similar cases, initial analysis might take a few hours. We will update you by this afternoon.” If it’s a severe issue, you might commit to more frequent updates. The key is not to promise unrealistic timelines; if you don’t know how long it will take, be transparent about that but assure them that it’s being treated with urgency. For instance, “We’ve marked this as a critical case with Microsoft. Their engineer is currently collecting data. We don’t have an ETA yet, but we will let you know as soon as we do. Expect an update from me in 2 hours even if it’s just to say we’re still working on it.” Even an update of “no new news” at a regular interval is better than silence.
Regular Status Updates: Throughout the life of the case, send periodic updates to the customer. The frequency should correspond to the impact and severity – in a total outage, every few hours or as agreed; in a less critical issue, maybe daily updates. These updates should summarize progress: what has been done recently (e.g., “We provided Microsoft with the log files they requested and they are analyzing them now”), what the current status is, and next steps or expected actions[11]. If Microsoft provided a potential workaround or asked for a test that involves the customer’s input, mention that too. For example, “Microsoft suggested a potential workaround. We implemented it on one affected user for testing, and it appears to restore email access. We are now rolling it out to all users as a temporary fix while Microsoft works on the root cause[11].” Such updates illustrate momentum and keep the customer in the loop.
Use Multiple Communication Channels (if appropriate): Determine the best way to reach your client for updates. Email is common for written status updates, but in urgent situations a phone call can be appreciated, especially for major milestones (like “We have a temporary fix, can we walk you through applying it?”). Some MSPs use client portals or dashboards where they post updates that clients can view at any time[11]. The medhacloud guidelines note using channels like email for detailed updates, phone for critical alerts, and even live chat for real-time queries during an ongoing incident[11]. Cater to your customer’s preferences and the severity of the scenario.
Be the Translator: Often you’ll get technical information from Microsoft that might be over the customer’s head. Part of expectation management is translating that into terms the customer understands and cares about. If Microsoft says, “We found a problem with Exchange Online service and they’re applying a fix on their backend,” you might tell the customer, “Microsoft identified an issue in their cloud email service and is deploying a fix. This likely means the issue was on Microsoft’s side. We expect the service to gradually recover within the next hour based on their update.” Keep it high-level – clients mainly want to know what impact or action for them and how much longer. Avoid forwarding raw technical logs or Microsoft’s lengthy explanations directly to business stakeholders who may not find it useful.
Provide Interim Solutions or Workarounds: If any workaround is available, inform the customer how they can use it to alleviate pain while the full fix is in progress. For example, “While Microsoft works on a permanent fix for the Outlook issue, users can access email through the Outlook Web App as a temporary solution.” Make sure they know this is temporary. Clients appreciate having options, even if not ideal, to keep business moving. Also, communicate any interim risk mitigations – e.g., “We’ve advised Microsoft this is an urgent issue for payroll processing, and in the meantime we’ve rolled back the software update that seemed to trigger the problem.” This level of detail shows proactive steps to reduce impact.
Stay Honest and Don’t Over-Promise: If things are taking longer than expected, let the customer know. It’s better to say “This is more complex than initially thought, but we are continuing to escalate with Microsoft; thank you for your patience” than to go quiet or give false assurances. By managing expectations, you maintain trust. Clients generally understand that some issues are outside anyone’s immediate control, especially if it’s on the vendor’s side, as long as they feel informed and involved. What frustrates customers most is feeling left in the dark or misled about progress.
Escalation Communication: If the customer is particularly high-stakes (say a VIP user or a business-critical system), you might involve their stakeholder in communications with Microsoft in some way. Sometimes on big calls you might invite a client’s IT representative to join. Or at least let them know, “We have escalated this to Microsoft’s senior engineers and even involved their product team due to the critical nature.” This again reinforces that you’re taking all possible actions. In extreme cases, the client might ask to speak with Microsoft support directly. Typically, as the MSP, you should remain the primary interface (both to control the flow of info and because you likely have the technical context), but you can arrange a joint call if needed.
Finally, when sending updates, highlight the good: “Microsoft has found the cause and is now deploying a fix,” but also be transparent about the not-so-good: “Their initial fix didn’t work, so the issue is still ongoing; we’ve escalated further.” It’s this trust through communication that defines a seamless support experience – even if the actual resolution takes time, the journey is managed in a way that the customer feels supported throughout[11]. In fact, effective communication during outages or issues often earns praise from clients, because it demonstrates reliability and commitment[11].
By properly managing customer expectations and keeping them informed, you ensure that when the issue is finally resolved, the customer remembers not just the problem, but also the professionalism and care with which it was handled.
Step 8: Verify Resolution and Ensure Recovery
After troubleshooting and collaboration with Microsoft Support, there will (hopefully) come a point where a solution or fix is identified. Step 8 is about executing that solution and verifying that it truly resolves the issue for the customer. It’s critical not to consider the case closed until both the MSP and the customer are confident that everything is back to normal.
Implement the Fix or Workaround: Microsoft might provide a fix in various forms – it could be a configuration change, a patch or update to apply, a command to run, or they might inform you that they have made a change on their side (in the cloud service) that should resolve the problem. Follow the instructions carefully. If it’s something you need to do on the customer’s environment (like adjusting a setting or installing a local update), schedule it at the earliest appropriate time (immediately for critical issues, or in a maintenance window for less urgent ones, coordinating with the client as needed). Document exactly what steps are taken to implement the fix.
For example, Microsoft might say: “We’ve identified a bug and applied a fix in the backend, please have the affected users restart Outlook.” In such a case, you’d proceed to have users restart and perhaps clear some cache as instructed. Or if they provided a script to fix mailbox permissions, run that and note the output.
Thorough Testing: After applying the fix, test the original issue scenario to confirm it is resolved. This should be done in a controlled way. If the issue was with a single user, work with that user to validate the fix (e.g., have them log in and confirm they can now send email, or that the error no longer appears). If it was a broader issue, test across a sample of affected users or systems. It’s often wise for the MSP to do their own test first, if possible, before saying to all end-users “go ahead, it’s fixed.” For instance, if SharePoint was down, test loading the site yourself and maybe ask one or two key users to retry and confirm performance is back. Don’t just take Microsoft’s word that it’s fixed – verify it in the real environment.
Ensure that all aspects of the problem are addressed: if the issue had multiple symptoms, check each one. Sometimes a fix might solve the primary error but reveal another minor issue, so you want to catch that before declaring victory. If the issue was time-sensitive (maybe causing backlog), also verify that any queued activities (like emails in queue, or pending tasks) have caught up once service is restored.
Customer Confirmation: Once your own testing suggests the problem is solved, reach out to the customer to confirm. Have the end-users try the scenario that was failing and report success. It’s important the end-user’s perspective is positive – maybe your test account works, but the user might do something slightly differently. When the customer confirms “Yes, everything works now, and I can do my job again,” you’ve achieved the main goal. This is also a good time to express empathy about the inconvenience and joy that it’s resolved: “I’m glad to report your email is functioning normally again. I apologize for the disruption, and we’re happy it’s been resolved.”
Restore Normal Operations: If any interim workarounds were in place (Step 7) or temporary measures enacted, remove or roll them back if appropriate. For example, if everyone was using webmail as a workaround, now that Outlook is fixed, ensure that’s communicated so they can go back to their usual workflow. If you deferred any maintenance or had to disable a feature temporarily, put things back to the regular state carefully.
It’s also wise at this stage to monitor the situation a bit longer even after the customer’s initial confirmation. If it’s a critical system, keep an eye on it for another day or two to be sure the issue doesn’t recur. Microsoft might close the case on their end as soon as they hear it’s fixed, but you can usually reopen within a short window if the issue comes back. Many support engineers will actually wait for you to confirm and might say “I’ll follow up tomorrow to ensure all is well before closing the ticket.” Use that safety net if offered.
Document the Outcome: Internally, note that the issue was resolved and how. Write a brief summary in your ticket: e.g., “Issue resolved on Microsoft’s end – root cause was a known bug in Exchange Online, Microsoft applied a fix at 3:00 PM. User confirmation received that email flows now work. Case #123456 closed.” This summary will be valuable later for your knowledge base and for any post-incident review (coming up in Step 9).
Microsoft often likes to confirm resolution as well; they might ask “Is it OK to close the case now?” Only agree once you are confident. If you need a day or two to be sure, you can tell them that and keep the case in monitoring status. Once confirmed, let them know and thank the support engineer for their assistance, which is good etiquette and helps maintain a good relationship.
In essence, Step 8 is about making sure “the patient is healthy” after the treatment. Just as a doctor would schedule a follow-up to ensure recovery, the MSP verifies that the fix delivered by Microsoft truly solved the issue and that the customer’s operations are back to normal. According to MSP resolution practices, this includes testing the fix and verifying with the client that everything is fully restored to normal operation[10]. Only then do we move on to closure and reflection.
Step 9: Close the Loop – Post-Incident Documentation and Actions
With the issue resolved and normalcy restored for the customer, the immediate fire is out. However, the process is not truly complete until you capture lessons learned and perform any follow-up tasks that can strengthen your service in the future. This step turns an incident into an opportunity for improvement and knowledge-building.
Document the Root Cause and Resolution: Work with the information from Microsoft and your own analysis to understand what exactly caused the issue. Sometimes Microsoft will explicitly tell you the root cause (for example: “A bug in the recent update caused a memory leak, which our engineering team has now fixed in the service” or “It turned out the customer’s mailbox was stuck due to a corrupt rule, which we removed”). Other times, the root cause might be “undetermined” especially if the solution was a workaround. Whatever the outcome, write down a clear description of the cause and the fix in your internal documentation[10]. If Microsoft provided a summary in an email or closure notes, you can use that as a starting point. Also include the case number and any important timelines (like “Outage from 10:00-14:00, resolved by Microsoft fix deployment”).
Add this information to your knowledge base or ticketing system in a way that’s easily searchable later. For instance, if you have a wiki or SharePoint for KB articles, create an article titled “Outlook clients failing to connect – July 2025 incident” that outlines the symptoms, cause, and resolution. This helps if the same or similar issue occurs again – your team can quickly reference what was done previously[10]. Even if the issue was a one-off, internal knowledge growth is invaluable.
Conduct a Post-Incident Review: For significant incidents, it’s a best practice to have a short internal meeting or debrief. Include the team members who worked on the issue and discuss questions like: What went well? What could have been done better?[10]. Perhaps your team reacted swiftly and communication was great (something to replicate next time), but maybe you realized you could have escalated to Microsoft 2 hours sooner than you did. Or maybe an internal monitoring system didn’t catch the issue early and you discuss how to improve that. Document any action items from this review, such as “implement better alerting” or “develop a checklist for future similar issues.”
It can also be useful to get the customer’s perspective: did they feel informed? If there were any complaints or confusion, incorporate that feedback. Many MSPs incorporate client feedback and internal retrospectives to refine their incident response process continually[11].
Update Internal Processes and Runbooks: If the incident revealed any gaps in your processes, now is the time to fix them. For example, if the team was uncertain how to contact Microsoft or wasted time figuring out how to gather certain logs, update your standard operating procedures to include those details for next time[9]. Make sure your internal documentation on “How to escalate to Microsoft” is up-to-date with correct phone numbers, portal instructions, etc. Possibly create a template for support requests that includes all the info from Step 3’s checklist so engineers have a guide for future cases.
Also, incorporate any new troubleshooting tips learned. If Microsoft taught you something (like a new PowerShell command or a hidden diagnostic tool), add that to your toolkit documentation. Each resolved case should enrich your MSP’s collective knowledge.
Preventive Measures: Determine if there are actions to prevent this issue from happening again (if preventable). For example, if the root cause was a misconfiguration on the customer side, you should correct that on all similar systems (e.g., fix that setting for all users, not just the one that had the issue). If it was a bug on Microsoft’s side, maybe there’s not much you can do except be aware. But sometimes Microsoft might provide guidance like “apply the latest patch” or “avoid using X feature until a fix is fully deployed.” Ensure those recommendations are followed through for your customer’s environment, and even across your other clients if applicable.
Measure and Record Key Metrics: It’s valuable to note metrics such as how long the issue lasted, the total time to resolution, and the downtime experienced. Also note how long the Microsoft support process took – e.g., case opened at 9 AM, first response at 9:30 AM, resolved at 3 PM. These metrics help assess the support experience and can be used to set expectations for the future or identify if something was unusually slow. Over time, tracking metrics like average resolution time for Microsoft tickets, number of cases per month, etc., can inform decisions (for instance, if you find support is too slow, maybe pushing for a higher support tier might be justified). Ultimately, the goal is minimizing downtime and quick resolution[10], so measuring these helps gauge success.
Communicate Closure to the Customer: Don’t forget to formally close the loop with the client as well. Send a final communication summarizing the resolution: “We have confirmed that the email issue is fully resolved. Microsoft identified the root cause as ___ and has addressed it. Your service was restored at [time]. We will be monitoring to ensure stability. Thank you for your patience.” This kind of wrap-up reassures the customer that the issue won’t linger. It also educates them on cause (which can help them understand if it was Microsoft’s fault, not the MSP’s, in a diplomatic way). If appropriate, schedule a follow-up meeting with the client, especially if it was a major incident, to review what happened and any next steps. This shows professionalism and dedication to continual improvement[11].
Feedback to Microsoft: If Microsoft sends a customer satisfaction survey for the support case, take the time to fill it out (or ask your customer to fill it out if it goes to them directly). Provide candid feedback on what went well and what didn’t. Microsoft does value this and it can influence the support they provide. If the support experience was great, recognize the engineer. If it was subpar, politely highlight the issues (e.g., “had to explain problem multiple times as it got passed around” or “initial response took too long”). This feedback can help Microsoft improve and also, as a partner, your feedback might be noted by account teams.
By diligently performing these post-incident activities, the MSP turns a resolved ticket into a stronger foundation for future support. Every incident becomes a learning opportunity. Over time, this means faster resolution and fewer escalations, as the team builds up a robust knowledge base and refined processes. It also demonstrates to the customer that you’re not just fixing and forgetting, but actively investing in preventing future issues – a hallmark of a proactive and reliable MSP.
Step 10: Continuous Improvement and Strengthening the Microsoft Partnership
The final step is an ongoing one – to leverage the experience gained and your relationship with Microsoft to improve future support interactions. A strong partnership with Microsoft and a well-trained team underpin a seamless support experience in the long run. This involves training, integration of support processes into your business, and nurturing the partnership.
Team Training and Knowledge Sharing: Take the lessons from the recent support issue and share them with the broader team. If only one engineer handled the case, ensure the others know what was learned. Conduct a short internal session or update your team newsletter/slack with “Support Case Spotlight” highlighting the key takeaways (cause of issue, how it was fixed, how we navigated Microsoft support). Emphasize any best practices that were validated, or new ones discovered. Over time, compile these into a playbook. Also, identify if there are skill gaps that training could fill. For example, if your team struggled to gather certain logs Microsoft needed, maybe a workshop on advanced M365 troubleshooting is in order.
Encourage your staff to pursue relevant Microsoft certifications or training courses. For M365, that could be certifications like MS-100 / MS-102 (Microsoft 365 Administrator) or specialists tracks for Exchange, SharePoint, Teams, etc. Certified staff are often better equipped to diagnose issues and speak Microsoft’s language when engaged in support. The benefits of ongoing training for MSP staff include faster issue identification and resolution (less downtime for clients) and being up-to-date on the latest technologies[12][12]. Additionally, vendor-specific training – i.e., training directly related to Microsoft tools and support processes – ensures your team is using Microsoft’s recommended methods effectively[12]. For instance, knowing how to use Microsoft’s advanced diagnostic tools or the latest admin center features could save precious time during an incident.
Integrate Microsoft Support Processes into MSP Operations: Make Microsoft support an extension of your own support workflow. This means having clear internal policies on when and how to escalate to Microsoft. Define triggers: e.g., “if an issue is cloud-related and not resolved in 30 minutes, consider opening a Microsoft case.” Ensure your ticketing system has a field or flag for ‘Escalated to Vendor/Microsoft’ and that engineers update it accordingly[9][9]. Track these tickets so you can report on them (how many vendor escalations, average resolution time, etc.).
Another aspect is to maintain a list of important Microsoft contacts or resources. For example, keep the support phone numbers handy, know your Tenant ID (often needed when calling support), and if you have a Microsoft Partner Center account, ensure your team knows how to use it to file support tickets on behalf of customers.
If you often work with Microsoft support, consider setting up regular reviews with Microsoft’s support/account team if available. Some Microsoft support plans (like Premier/Unified Support) offer quarterly service reviews where they look at your cases, patterns, and can advise how to reduce incidents. Even if you don’t have that, as a partner you might have a partner manager who can provide insights or escalation assistance when needed.
Leverage Microsoft Partner Programs: SMB MSPs that are Microsoft partners should take full advantage of the support-related benefits in those programs. For instance, if you have a Microsoft Action Pack or Solutions Partner designation, you might have some Azure or M365 support incidents included or access to Advanced Support for Partners at a discount. Evaluate if upgrading your support plan with Microsoft makes sense. Microsoft Premier/Unified Support for Partners, for example, offers faster response times, dedicated account management, and proactive services[8][8]. Benefits of such a relationship include having a designated escalation manager and access to workshops that can prevent issues[8]. If you faced a very painful downtime that could have been mitigated by faster Microsoft response, that’s a business case to invest in a higher support tier.
Even without a paid support plan, being a partner means you can sometimes access the Microsoft Partner Support Community or get delegate admin access to customer tenants which streamlines support interactions. Stay connected with Microsoft’s communications – for example, partner newsletters or the M365 roadmap alerts – so you’re aware of upcoming changes that could affect clients, thus preventing some support issues proactively.
Building Relationships: Over time, try to build a rapport with Microsoft support personnel and teams. While support cases are transactional, you might frequently interact with certain regional support teams. Professionalism and constructive interactions may make them a bit more attentive to future cases (support engineers sometimes remember helpful customers/partners). If you have a Technical Account Manager (TAM) through a support contract, maintain regular contact, not just during crises. A TAM can champion your cause internally.
Continuous Feedback Loop: Keep soliciting feedback from your customers about how they feel support is going (this can be part of a quarterly business review: discuss any major support incidents and how they were handled). Use that to tweak your approach. And likewise, provide feedback to Microsoft via any channel available. Microsoft has feedback forums and often after closing a case, they’ll send a survey – use those to voice your experience. If you encountered a particularly outstanding or poor support experience, Microsoft should hear about it. This helps them improve and also can indirectly benefit you as future cases might be handled with lessons learned from that feedback.
Finally, stay proactive. The best support issue is the one that never happens. Use what you learn from past incidents to implement monitoring or preventive fixes for other clients. For example, if one customer had a misconfigured setting that caused a support ticket, audit your other customers for that same setting. Engage with Microsoft’s preventive resources: they publish best practice analyzers and health checks (like Secure Score, Microsoft 365 Apps health, etc.). Proactively fixing things reduces the number of times you need to call Microsoft at all.
In conclusion, by continuously refining your internal processes and nurturing your partnership with Microsoft, you create a virtuous cycle. Each support case not only gets resolved but makes the next one easier or less likely. Your team becomes more skilled, your relationship with Microsoft more collaborative, and your customers more confident in your service. An MSP that effectively integrates vendor support into its own workflow stands out for delivering reliable, end-to-end support experiences – exactly what clients expect when they entrust you with their IT needs.
Conclusion
Optimizing the support process as an SMB MSP when working with Microsoft is all about preparation, communication, and continuous improvement. By following a structured step-by-step approach – from diligent initial troubleshooting and comprehensive case documentation, through effective engagement with Microsoft support, to thorough resolution verification and post-incident analysis – an MSP can ensure that issues are resolved as swiftly as possible with minimal customer impact.
Best practices like providing detailed information, maintaining open lines of communication with both Microsoft and your customer, and knowing how to navigate escalations make the support experience smoother for everyone involved. Implementing these processes not only speeds up individual issue resolution but also strengthens the MSP’s overall service capability. Over time, your team will become more adept at handling M365 problems (preventing many outright), and your working relationship with Microsoft support will become more efficient and collaborative.
In essence, a seamless support experience results from being proactive and methodical: anticipate what Microsoft will need and have it ready, keep all stakeholders informed, and never stop refining your approach. By doing so, you demonstrate to your customers that even when issues arise, they are in capable hands – you and Microsoft’s – working together to keep their business running smoothly. With each resolved case and each improvement in process, you build trust and reliability, solidifying your reputation as a responsive and effective managed service provider.
Blocking Applications on Windows Devices using Intune (M365 Business Premium)
Managing which applications can run on company devices is crucial for security and productivity. Microsoft Intune (part of Microsoft 365 Business Premium) offers powerful ways to block or restrict applications on Windows 10/11 devices. This guide explains the most effective method – using Intune’s Mobile Device Management (MDM) with AppLocker – in a step-by-step manner. We also cover an alternative app-level approach using Intune’s Mobile Application Management (MAM) for scenarios like BYOD.
Introduction and Key Concepts
Microsoft Intune is a cloud-based endpoint management service (included with M365 Business Premium along with Azure AD Premium P1) that provides both MDM and MAM capabilities[1]. In the context of blocking applications on Windows:
MDM (Mobile Device Management) means the Windows device is enrolled in Intune, allowing IT to enforce device-wide policies. With MDM, you can prevent an application from launching at all on the device[1][1]. Attempting to run a blocked app will result in a message like “This app has been blocked by your system administrator”[1]. This is ideal for corp-owned devices where IT has full control.
MAM (Mobile Application Management) uses App Protection Policies to protect corporate data within apps without full device enrollment. Instead of stopping an app from running, MAM blocks the app from accessing or sharing company data[1][1]. Users can install any app for personal use, but if they try to open corporate content in an unapproved app, it will be prevented or the data will remain encrypted/inaccessible[1]. This is suited for BYOD scenarios.
Most Effective Method: In a typical small-business with M365 Business Premium, the MDM approach with AppLocker is the most direct way to block an application on Windows devices – it completely prevents the app from launching on managed PCs[1][1]. The MAM approach is effective for protecting data (especially on personal devices) but does not physically stop a user from installing or running an app for personal use[1]. Often, MDM is used on corporate devices and MAM on personal devices to cover both scenarios without overreaching on user’s personal device freedom[1][1].
Prerequisites and Setup
Before implementing application blocking, make sure you meet these prerequisites[1][1]:
Intune License: You have an appropriate Intune license. Microsoft 365 Business Premium includes Intune, so if you have M365 BP, you’re covered on licensing and have the necessary admin access to the Intune admin center[1][1].
Supported Windows Edition: Devices should be running Windows 10 or 11 Pro, Business, or Enterprise editions. (Windows Home is not supported for these management features[1].) Ensure devices are up to date – recent Windows 10/11 updates allow AppLocker enforcement even on Pro edition (the historical limitation to Enterprise has been removed)[1][1].
Device Enrollment (for MDM): For device-based blocking, Windows devices must be enrolled in Intune (via Azure AD join, Hybrid AD join, Autopilot, or manual enrollment)[1]. Enrollment gives Intune the control to push device configuration policies that block apps.
Azure AD and MAM Scope (for app protection): If using app protection (MAM) policies, users should exist in Azure AD and you need to configure the MAM User Scope so Intune can deliver app protection to their devices[1]. In Azure AD -> Mobility (MDM and MAM), set Intune as the MAM provider for the relevant users/groups. (Typically, for BYOD scenarios you might set MDM scope to a limited group or none, and MAM scope to all users[1].)
Administrative Access: Ensure you have Intune admin permissions. Log into the https://endpoint.microsoft.com (also known as Microsoft Endpoint Manager portal) with an admin account to create policies[1].
Test Environment: It’s wise to have a test or pilot device/group enrolled in Intune to trial the blocking policy before broad deployment[1]. Also, identify the application(s) you want to block and have one installed on a test machine for creating the policy.
With the basics in place, we can proceed with the blocking methods.
Method 1: Block Applications via Intune MDM (AppLocker Policy)
Overview: Using Intune’s device (MDM) capabilities, we will create an AppLocker policy to block a specific application and deploy that policy through Intune. AppLocker is a Windows feature that allows administrators to define which executables or apps are allowed or denied. Intune can deliver AppLocker rules to managed devices, effectively preventing targeted apps from running[1][1].
Create an AppLocker rule on a reference Windows PC to deny the unwanted application.
Export the AppLocker policy to an XML file.
Create an Intune Device Configuration profile (Custom OMA-URI) in the Intune portal and import the AppLocker XML.
Assign the profile to the target devices or user group.
Monitor enforcement and adjust if necessary.
We will now go through these steps in detail:
Step 1: Create & Export an AppLocker Policy (Blocking Rule)
First, on a Windows 10/11 PC (your own admin machine or a lab device), set up the AppLocker rule to block the chosen application:
Open Local Security Policy: Log in as an administrator on the reference PC and run “Local Security Policy” (secpol.msc). Navigate to Security Settings > Application Control Policies > AppLocker[1].
Enable AppLocker & Default Rules: Right-click AppLocker and select “Properties.” For each rule category (Executable, Script, Windows Installer (.msi), Packaged app (*.appx)), check “Configured” and set it to “Enforce rules”, then click OK[1]. Next, create the default allow rules for each category: e.g., right-click Executable Rules and choose “Create Default Rules.” This adds baseline allow rules (e.g., allow all apps in %ProgramFiles% and Windows directories, and allow Administrators to run anything) so that you don’t inadvertently block essential system files or admin actions[1][1]. (Ensuring default rules exist is crucial to avoid locking down the system accidentally.)
Create a Deny Rule for the Application: Decide which app to block and under the appropriate category, right-click and select “Create New Rule…”[1]. This launches the AppLocker rule wizard:
Action: Choose “Deny” (we want to block the app)[1].
User or Group: Select “Everyone” (so the rule applies to all users on the device)[1]. (Alternatively, you could target a specific user or group if needed.)
Condition (Identification of the app): If it’s a classic Win32 app (an EXE), you can choose a Publisher rule (recommended for well-known signed apps), a Path rule, or a File hash rule. For a well-known signed app (e.g., Chrome, Zoom), choosing Publisher is ideal so that all versions of that app from that publisher get blocked[1][1]. You will be prompted to browse for the app’s executable on the system – select the main EXE (for example, chrome.exe in C:\Program Files\Google\Chrome\Application\chrome.exe for Google Chrome)[1][1]. The wizard will read the digital signature and populate the publisher and product info. You can adjust the slider to define the scope (e.g., blocking any version of Chrome vs. a specific version) – typically, slide to “File name” or “Product” level to block all versions of that app[1]. If blocking a Microsoft Store (UWP) app, switch to Packaged app Rules and select the app from the list of installed packages (e.g., TikTok if installed from Store)[1]. This will use the app’s package identity as the condition. (If the app isn’t installed on your ref machine to select, you can use a File hash, but Publisher rules are easier to maintain when possible[1].)
Complete the wizard by giving the rule a name and optional description (e.g., “Block Chrome”) and finish. You should now see your new Deny rule listed under the appropriate AppLocker rule category[1] (e.g., under Executable Rules for a .exe).
Confirm Rule Enforcement: Ensure AppLocker enforcement is enabled (the earlier step of setting to Enforced in Properties should handle this). With the deny rule created and default allow rules in place, the local policy will block the chosen app on this test machine.
Export the Policy: Now export these AppLocker settings to an XML file so we can deploy them via Intune. In the AppLocker console, right-click the AppLocker node and choose “Export Policy.” Save the file (e.g., BlockedApps.xml)[1][1]. This XML contains all AppLocker rules you configured.Tip: We only need the relevant portion of the XML for the rule category we configured (to avoid conflicts with categories we didn’t use). For example, if we only created an Executable rule, open the XML in a text editor and find the <RuleCollection Type="Exe" EnforcementMode="Enabled"> ... </RuleCollection> section[1]. Copy that entire <RuleCollection> block to use in Intune[1]. (Similarly, if blocking a packaged app, use the <RuleCollection Type="AppX"...> section, etc.) This way, we import just the necessary rules into Intune without overriding other categories that we didn’t configure[1][1].
Step 2: Deploy the AppLocker Policy via Intune
Now that we have our AppLocker XML snippet, we’ll create a Custom Device Configuration Profile in Intune to deliver this policy to devices:
Create a Configuration Profile in Intune: Log in to the Intune admin center (Endpoint Manager portal) and navigate to Devices > Configuration Profiles (or Devices > Windows > Configuration Profiles). Click + Create profile.
Platform: Select Windows 10 and later.
Profile type: Choose Templates > Custom (because we’ll input a custom OMA-URI for AppLocker)[1][1].
Click Create and give the profile a name (e.g., “Block AppLocker Policy”) and an optional description[1][1].
Add Custom OMA-URI Settings: In the profile editor, under Configuration settings, click Add to add a new setting. Enter the following details for the custom setting:
Name: A descriptive name like “AppLocker Exe Rule” (if blocking an EXE) or “AppLocker Store App Rule” depending on your target[1][1].
OMA-URI: This is the path that Intune uses to set the AppLocker policy via the Windows CSP. Use the path corresponding to your rule type:
For executable (.exe) apps:\ ./Vendor/MSFT/AppLocker/ApplicationLaunchRestrictions/Apps/EXE/Policy[1].
For Microsoft Store (packaged) apps:\ ./Vendor/MSFT/AppLocker/ApplicationLaunchRestrictions/Apps/StoreApps/Policy[1].
(If you were blocking other types, there are similar OMA-URI paths for Script, MSI, DLL under AppLocker CSP, but most common cases are EXE or StoreApps.)
Data type: Select String (we’ll be uploading the XML as a text string)[1].
Value: Paste the XML content of the <RuleCollection> that you copied earlier, including the <RuleCollection ...> tags. This is essentially the AppLocker policy definition in XML form[1]. Double-check that you included the opening and closing tags and that the XML is well-formed. (Intune will accept the large XML string here – if there’s a syntax error in the XML, the policy might fail to apply.)
Click Save after adding this OMA-URI setting.
Complete Profile Creation: Click Next if additional pages appear (for Scope tags, etc., usually can leave default). On Assignments, choose the group of devices or users to which this blocking policy should apply:
For initial testing, you might assign it to a small pilot group or a single device group (perhaps an “IT Test Devices” group).
For full deployment, you could assign to All Devices or a broad group like “All Windows 10/11 PCs” if all devices should have this app blocked[1]. (Consider excluding IT admin devices or others if you need to ensure they can run the app, but generally “Everyone” was set in the rule so any device that gets this policy will block the app for all users on it.)
After selecting the group, click Next through to Review + Create, then click Create to finish creating the profile[1][1].
Intune will now deploy this policy to the targeted Windows endpoints. Typically, devices check in and apply policies within minutes if online (or the next time they come online).
Step 3: Policy Assignment and Enforcement
Once the profile is created and assigned, Intune will push the AppLocker policy to the devices. On each device:
The policy is applied via the Windows AppLocker Configuration Service Provider (CSP). When the device receives the policy, Windows integrates the new AppLocker rule.
If the user attempts to launch the blocked application, it will fail to open. On Windows, they will see a notification or error dialog stating the app is blocked by the administrator or system policy[1][1]. Essentially, the app is now inert on those machines – nothing happens when they try to run it (or it closes immediately with a message).
To summarize the MDM enforcement: the application itself is blocked from running on the device – the user cannot launch it at all on a managed, compliant device[1]. This provides a strong guarantee that the software can’t be used (preventing both intentional use and accidental use of unauthorized apps).
Example: If we deployed a policy to block Google Chrome, any attempt to open Chrome on those Intune-managed PCs will be prevented. The user will typically see a Windows pop-up in the lower-right saying something like “ has been blocked by your organization”[1]. They will not be able to use Chrome unless the policy is removed.
Note: Intune/MDM-based AppLocker policies apply to any user on the device by default. If multiple users use the same PC (as Azure AD users), the blocked app will be blocked for all (since we set the rule for Everyone). Keep this in mind if any shared devices are in scope.
Step 4: Testing, Monitoring and Verification
After deploying the policy, it’s important to verify it’s working correctly and monitor device compliance:
Test on a Pilot Device: On a test device that received the policy, try launching the blocked application. You should confirm that it does not run and that you receive the expected block message[1][1]. If the app still runs, double-check that the device is indeed Intune-managed, in the assigned group, and that the policy shows as successfully applied (see below).
Intune Policy Status: In the Intune admin center, go to the Configuration Profile you created and view Device status or Per-user status. Intune will report each targeted device with status “Succeeded” or “Error” for applying the policy[1][1]. Verify that devices show Success for the AppLocker profile. If there are errors, click on them to get more details. A common error might be malformatted XML or an unsupported setting on that OS edition.
Event Logs: On a Windows client, you can also check the Windows Event Viewer for AppLocker events. Look under Application and Services Logs > Microsoft > Windows > AppLocker > EXE and DLL. A successful block generates an event ID 8004 (“an application was blocked by policy”) in the AppLocker log[1][1]. This is useful for auditing and troubleshooting – you can see if the rule fired as expected. If you see event 8004 for your app when a user tried to open it, the policy is working.
Monitor Impact: Ensure no critical application was inadvertently affected. Thanks to the default allow rules, your policy should not block unrelated apps, but it’s good to get feedback from pilot users. Have IT or a pilot user attempt normal work and ensure nothing else is broken. If something necessary got blocked (e.g., perhaps the rule was too broad and blocked more than intended), you’ll need to adjust the AppLocker rule criteria (see Step 5).
Common issues and troubleshooting:\ Even with a straightforward setup, a few issues can arise:
Correct App Identification: Make sure the rule accurately identifies the app. If using a publisher rule for an EXE, it should cover all versions. If the app updates and the publisher info remains the same, it stays blocked. If you used a file hash rule, a new version (with a different hash) might bypass it – so publisher rules are generally preferred for well-known apps[1][1]. For Store apps, ensure you selected the correct app package or used the correct Package Family Name. Microsoft documentation suggests using the Store for Business or PowerShell to find the precise Package Identity if needed[1].
Application Identity Service: Windows has a service called Application Identity (AppIDSvc) that AppLocker relies on to function. This service should start automatically when AppLocker policies are present. If it’s disabled or not running, AppLocker enforcement will fail. Ensure the service is not disabled on your clients[1][1]. (By default it’s Manual trigger-start – Intune’s policy should cause it to run as needed.)
Windows Edition: Remember that Windows Home edition cannot enforce AppLocker policies[1]. Pro, Business, or Enterprise should be fine (if fully updated). If a device is not enforcing the policy, check that it’s not a Home edition.
Default Rules: Always have the AppLocker default allow rules in place (or equivalent allow rules) for all categories you enforce, otherwise you might end up blocking the OS components or all apps except your deny list. If you skipped creating default rules, go back and add them, then re-export the XML. Missing default rules can lead to “everything is blocked” scenarios which require recovery.
Multiple Policies: In Intune, if you apply multiple AppLocker policies (say two different profiles targeting the same device), they could conflict or override each other[1]. It’s best to consolidate blocked app rules into one policy if possible. If you must use separate policies for different groups, ensure they target mutually exclusive sets of devices or users. In a small business, one AppLocker policy for all devices is simpler[1].
Policy Application Timing: Intune policies should apply within a few minutes, but if a device is offline it will apply next time it connects. You can trigger a manual sync from the client (Company Portal app or in Windows settings under Work & School account > Info > Sync) to fetch policies immediately.
Step 5: Maintaining and Updating the Block Policy
Over time, you may need to adjust which applications are blocked (add new ones or remove some):
Updating the Policy: To change the list of blocked apps, you have two main options:
Edit the AppLocker XML: On your reference PC, you can add or remove AppLocker rules (for example, create another Deny rule for a new app, or delete a rule) and export a new XML. Then, in Intune, edit the existing configuration profile – update the XML string in the Custom OMA-URI setting to the new XML (containing all current rules)[1][1]. Save and let it repush. The updated policy will overwrite the old rules on devices.
Create a New Profile: Alternatively, you could create a new Intune profile for an additional blocked app. However, as noted, multiple AppLocker profiles can conflict. If it’s a completely separate rule set, Intune might merge them, but to keep things simple, it’s often easier to maintain one XML that contains all blocked app rules and update it in one profile[1]. For example, maintain a “BlockedApps.xml” with all forbidden apps listed, and just update that file and Intune profile as needed.
Removing a Block: If an application should no longer be blocked (e.g., business needs change or a false alarm), you can remove the rule from the AppLocker XML and update or remove the profile. Removing the Intune profile will remove the AppLocker policy from devices (restoring them to no AppLocker enforcement)[1][1]. However, note that Intune’s configuration profiles sometimes “tattoo” settings on a device (meaning the setting remains even after the profile is removed, until explicitly changed)[2]. AppLocker CSP settings typically are removed when the profile is removed while the device is still enrolled. If a device was removed from Intune without first removing the policy, the block might persist. In such a case, you’d need to either re-enroll and remove via Intune, or use a local method to clear AppLocker policy. Microsoft’s guidance for Windows Defender Application Control (WDAC) suggests deploying an “Allow all” policy to overwrite a blocking policy, then removing it[2]. Similarly, for AppLocker, the cleanest removal is: (a) push an updated policy that doesn’t have the deny rule (or explicitly allows the app), then (b) remove that policy. So, plan the removal carefully to avoid orphaned settings.
Communication to Users: When implementing or updating blocked apps, inform your users in advance if possible. Users might encounter a blocked application message and create helpdesk tickets if they weren’t expecting it. Ensure that your organizational policy documentation lists which apps are disallowed and why (e.g. security or compliance reasons), so employees know the rules. If an important app is blocked, have a process for exception requests or review.
User Support: Be prepared to handle cases where a user says “I need this app for my work.” Evaluate if that app can be allowed or if there’s an approved alternative. Sometimes an app might be blocked for most users but certain roles might need it – in such cases, consider scoping the Intune policy to exclude those users or create a separate policy for them with a different set of rules.
Best Practices:
Pilot first, then deploy broad: As emphasized, always test your blocking policy on a limited set of machines before rolling out company-wide[1]. This prevents any nasty surprises (like blocking critical software).
Document and Align with Policies: Ensure that the list of blocked apps aligns with written company security policies or compliance requirements. For example, many organizations ban apps like BitTorrent or certain social media or games for compliance/security[3]. Some bans might be regulatory (e.g., government directives to ban specific apps due to security concerns[4]) – make sure your Intune policies support those mandates.
Gather feedback: After deploying, gather feedback from users or IT support about any impact. Users should generally not be impacted outside of being unable to use the forbidden app (which is intended). If there’s confusion or pushback, it might require management communication – e.g., explaining “We blocked XYZ app because it poses a security risk or is against company policy.”
Alternative Device-Based Protections (Compliance & Conditional Access)
In addition to AppLocker, Intune provides a few other mechanisms to deter or react to forbidden apps on devices:
Compliance Policy with Script: Intune compliance policies for Windows can detect certain conditions and mark a device non-compliant if criteria are met. While there isn’t a built-in “app blacklist” compliance setting for Windows, admins can use custom compliance scripts to check for the presence of an .exe. For instance, a PowerShell script could check if a disallowed app is installed, and if yes, set the device’s compliance status accordingly[1]. Then you could create an Azure AD Conditional Access policy to block non-compliant devices from accessing corporate resources. This approach does not directly stop the app from running, but it creates a strong incentive for users not to install it: their device will lose access to email, Teams, SharePoint, etc., if that app is present[1][1]. This is more complex to set up and punitive rather than preventive, but can be useful for monitoring and enforcing policy on devices where you might not be ready to hard-block apps.
Microsoft Defender for Endpoint Integration: If your M365 Business Premium includes Defender for Endpoint P1, note that P1 doesn’t have all app control features of P2, but one thing you can do is use Defender for Endpoint (MDE) for network blocking. For example, if the unwanted “app” is actually accessing a service via web, you can use MDE’s Custom Network Indicators to block the URL or domain (which also prevents usage of that service or PWA)[4][4]. Microsoft’s guidance for the DeepSeek app, for instance, shows blocking the app’s web backend via Defender for Endpoint network protection, so even if installed it can’t connect[4][4]. MDE can also enforce web content filtering across browsers (with network protection enabled via Intune’s Settings Catalog)[4][4].
App Uninstall via Intune: If an unwanted app was deployed through Intune (for example, a store app pushed earlier), Intune can also uninstall it by changing the assignment to “Uninstall” for that app[4][4]. However, Intune cannot directly uninstall arbitrary software that it did not install. For Win32 apps not deployed by Intune, you’d need to use scripts or other tools if you wanted to actively remove them. In many cases, simply blocking execution via AppLocker (and leaving the stub installed) is sufficient and less disruptive[1][1].
These alternatives can complement the primary AppLocker method, but for immediate prevention, AppLocker remains the straightforward solution on managed devices[1].
Method 2: Block Applications via Intune MAM (App Protection for Data)
For scenarios where devices are not enrolled (personal PCs) or you prefer not to completely lock down the device, Intune’s App Protection Policies provide a way to ensure corporate data never ends up in unapproved apps. This doesn’t stop users from installing or running apps, but it effectively blocks those apps from ever seeing or using company information[1][1]. In practice, an unapproved app becomes useless for work – e.g., a user could install a personal Dropbox or a game on their BYOD PC, but they won’t be able to open any work files with it or copy any text out of Outlook into that app.
This approach uses a feature formerly known as Windows Information Protection (WIP) for Windows 10/11, integrated into Intune’s App Protection Policies. M365 Business Premium supports this since it includes the necessary Intune and Azure AD features.
Key points about MAM data protection:
It works by labeling data as “enterprise” vs “personal” on the fly. Any data from corporate sources (e.g., Office apps signed in with work account, files from OneDrive for Business, emails in Outlook) is considered corporate and is encrypted/protected when at rest on the device.
You define a set of “protected apps” (also called allowed apps) that are approved to access corporate data (typically Office apps, Edge browser, etc.)[1][1]. Only these apps can open or handle the corporate data.
If a user tries to open a corporate document or email attachment in an app not on the allowed list, it will be blocked — either it won’t open at all, or it opens encrypted gibberish. Similarly, actions like copy-paste from a work app to a personal app can be blocked[1][1].
Unlike MDM, this doesn’t require device enrollment. You can apply it to any Windows device where a user logs in with a work account in an app (Azure AD registered). Enforcement is strengthened by pairing with Conditional Access policies to ensure they can only access, say, O365 data if they are using a protected app[1].
This is ideal for BYOD: the user keeps full control of their device and personal apps, but the company data stays within a managed silo.
Note: Microsoft has announced that Windows Information Protection (WIP) is being deprecated eventually[1]. It’s still supported in current Windows 10/11 and Intune, so you can use it now, but be aware that long-term Microsoft is focusing on solutions like Purview Information Protection and other DLP (data loss prevention) strategies[1][1]. As of this writing, WIP-based MAM policies are the main method for protecting Windows data on unenrolled devices.
Step-by-Step: Configure Intune App Protection (MAM) Policy for Windows
Follow these steps to set up a policy that will “protect” corporate data and block its use in unapproved apps:
1. Enable MAM for Windows in Azure AD (if not already):\ In the Azure AD (Entra) admin center, ensure Intune MAM is activated for Windows users:
Navigate to Azure AD > Mobility (MDM and MAM). Find Microsoft Intune in the MAM section.
Set the MAM User Scope to include the users who will receive app protection (e.g., All users, or a specific group)[1][1]. This allows those users to use Intune App Protection on unenrolled devices.
Ensure the MDM User Scope is configured as you intend. For example, in a BYOD scenario, you might set MDM user scope to None (so personal devices don’t auto-enroll) and MAM user scope to All. In a mixed scenario, you can have both scopes enabled; an unenrolled device will simply only get MAM policies, whereas an enrolled device can have both MDM and MAM policies (though device-enrolled Windows will prefer device policies)[1][1].
2. Create a Windows App Protection Policy:\ In the Intune admin center:
Go to Apps > App protection policies and click Create Policy.
It will ask “Windows 10 device type:” – choose “Without enrollment” for targeting BYOD/personal devices (this means the policy applies via MAM on Azure AD-registered devices, not requiring full Intune enrollment)[1]. (If you also want to cover enrolled devices with similar restrictions, you could create a separate policy “with enrollment.” For now, we’ll assume without enrollment for personal device usage.)
Give the policy a Name (e.g., “Windows App Protection – Block Unapproved Apps”) and a description[1].
**3. Define *Protected Apps* (Allowed Apps):**\ Now specify which applications are considered *trusted for corporate data*. These apps will be allowed to access organization data; anything not in this list will be treated as untrusted.
In the policy settings, find the section to configure Protected apps (this might be under a heading like “Allowed apps” or similar). Click Add apps[1].
Intune provides a few ways to add apps:
Recommended apps: Intune offers a built-in list of common Microsoft apps that are “enlightened” for WIP (e.g., Office apps like Outlook, Word, Excel, PowerPoint, OneDrive, Microsoft Teams, the Edge browser, etc.). You can simply check the ones you want to allow (or Select All to allow the full suite of Microsoft 365 apps)[1][1]. This covers most needs: you’ll typically include Office 365 apps and Edge. Edge is particularly important if users access SharePoint or web-based email – Edge can enforce WIP, whereas third-party browsers cannot[1].
Store apps: If there’s a Microsoft Store app not in the recommended list that you need to allow, you can add it by searching the store. You’ll need the app’s Package Family Name and Publisher info. Intune’s interface may allow selection from the Store if the app is installed on a device or via the Store for Business integration[1][1].
Desktop apps (Win32): You can also specify classic desktop applications to allow by their binary info. This requires providing the app’s publisher certificate info and product name or file name. For example, if you have a specific line-of-business app (signed by your company), you can allow it by publisher name and product name so it’s treated as a protected app[1][1]. This can also be used to allow third-party apps (e.g. perhaps Adobe Acrobat, if you trust it with corporate data).
After adding all needed apps, you’ll see your list of protected apps. Common ones: Outlook, Word, Excel, PowerPoint, Teams, OneDrive, SharePoint, Skype for Business (if used), Edge. The idea is to include all apps that you want employees to use for work data. Data will be protected within and between these apps.
(Optional) Exempt Apps: Intune allows designation of exempt apps which bypass WIP entirely (meaning they can access corporate data without restriction)[1]. Generally do NOT exempt any app unless absolutely necessary (e.g., a legacy app that can’t function with encryption). Exempting defeats the purpose by allowing data leakage, so ideally leave this empty[1][1].
4. Configure Data Transfer Restrictions:\ The policy will have settings for what actions are allowed or blocked with corporate data:
Key setting: “Prevent data transfer to unprotected apps” – set this to Block (meaning no sharing of data from a protected app to any app that isn’t in the protected list)[1]. This ensures corporate content stays only in the allowed apps.
Clipboard (Cut/Copy/Paste): You likely want to Block copying data from a protected app to any non-protected app[1]. Intune might phrase this as “Allow cut/paste between corporate and personal apps” – set to Block, or “Policy managed apps only”.
Save As: Block users from saving corporate files to unmanaged locations (e.g., prevent “Save As” to a personal folder or USB drive). In Intune, this might be a setting like “Block data storage outside corporate locations”[1].
Screen capture: You can disable screenshots of protected apps on Windows. This might be less straightforward on Windows 10 (since WIP can do it on enlightened apps). Set Block screen capture if available[1].
Encryption: Ensure Encrypt corporate data is enabled so that any work files saved on the device are encrypted and only accessible by protected apps or when the user is logged in with the right account[1].
Application Mode (Enforcement level): WIP had modes like Block, Allow Overrides, Silent, Off[1]. In Intune’s UI, this might correspond to a setting called “Protection mode”. You will want Block mode for strict enforcement (no override)[1][1]. Allow Overrides would prompt users but let them bypass (not desirable if your goal is full blocking of data transfer). Silent would just log but not prevent. So choose the strictest option to truly block data leakage.
There are other settings like “Protected network domains” where you specify which domains’ data is considered corporate (often your Office 365 default domains are auto-included, e.g., anything from @yourcompany.com email or SharePoint site is corporate). Intune usually auto-populates these based on your Azure AD tenant for Windows policies. Double-check that your organization’s email domain and SharePoint/OneDrive domains are listed as corporate identity sources.
Set any other policy flags as needed (there are many options, such as requiring a PIN for access to protected apps after a idle time, etc., but those are more about app behavior than data transfer).
5. (Optional) Conditional Launch Conditions:\ Intune’s app protection policies may allow you to set conditional launch requirements – e.g., require device to have no high-risk threats detected, require devices to be compliant, etc. For Windows, a notable one is integrating with Microsoft Defender:
You could require that no malware is present or device is not jailbroken (not as relevant on Windows), or if malware is detected, you can have the policy either block access or wipe corporate data from the app[1][1].
These settings can enhance security (ensuring the app won’t function if the device is compromised). They rely on Defender on the client and can add complexity. Use as needed or stick to defaults for now[1][1].
6. Assign the App Protection Policy:\ Unlike device config which targets devices, app protection policies target users (because they apply when a user’s account data is in an app).
Choose one or more Azure AD user groups that should receive this policy[1]. For example, “All Employees” or all users with a Business Premium license. In a small business, targeting all users is common, so any user who signs into a Microsoft 365 app on a Windows device will have these rules applied.
If you want to pilot, you could target only IT or a subset first.
7. Enforce via Conditional Access (CA):\ This step is crucial: to ensure that users actually use these protected apps and not find a workaround, use Azure AD Conditional Access:
Create a CA policy that targets the cloud apps you want to secure (Exchange Online, SharePoint Online, Teams, etc.).
In conditions, scope it to users or groups (likely the same users you target with the MAM policy).
In Access controls, require “Approved client app” or “Require app protection policy” for access[1]. In the CA settings, Microsoft 365 services have a condition like “Require approved client app” which ensures only apps that are Intune-approved (they have a list, e.g., Outlook, Teams mobile, etc.) can be used. On Windows, a more fitting control is Require app protection policy (which ensures that if the device is not compliant (MDM-enrolled), then the app being used must have an app protection policy).
One common approach: Require managed device OR managed app. This means if a device is Intune enrolled (compliant), fine – they can use any client. If not, then the user must use a managed (MAM-protected) app to access. For example, you could say: if not on a compliant (MDM) device, then the session must come from an approved client app (which essentially enforces app protection; on Windows this correlates to WIP-protected apps)[1][1].
This ensures that if someone tries to use a random app or an unmanaged browser to access, say, Exchange or SharePoint, they will be blocked. They’ll be forced to use Outlook or Edge with the app protection policy in place.
Without CA, the user could potentially use web access as a loophole (e.g., log into Outlook Web Access via Chrome on an unmanaged device). CA closes that gap by requiring either the device to be enrolled or the app to be a known protected app.
8. User Experience and Monitoring:\ Once deployed, the user experience on a personal Windows device with this policy is:
The user can install Office apps or use the Office web, but if they try to use a non-approved app for corp data, it won’t work. For example, if they try to open a corporate SharePoint file in WordPad or copy text from Outlook to Notepad, the action will be blocked by WIP (they might just see nothing happens or a notice saying the action is not allowed).
They might see a brief notification like “Your organization is protecting data in this app” when they first use a protected app[1].
Their personal files and apps are unaffected. They can still use personal email or personal versions of apps freely; the protection only kicks in for data that is tagged as corporate (which originates from the company accounts)[1][1].
If they attempt something disallowed (like pasting company data into a personal app), it will silently fail or show a message. These events can be logged.
Admins should monitor logs to ensure the policy works:
Intune App Protection Reports: Intune provides some reporting for app protection policies (e.g., under Monitor section for App Protection, you might see reports of blocked actions).
Event Logs on device: WIP events might be logged in the local event viewer under Microsoft->Windows->EDP (Enterprise Data Protection).
Azure AD Sign-in logs: If Conditional Access is used, sign-in logs will show if a session was blocked due to CA policy, which helps confirm that CA rules are working[1][1].
Periodically review these logs, and also gather any user feedback if they experience prompts or have trouble accessing something so you can fine-tune the allowed app list or policy settings.
9. Maintain the MAM Policy:\ If you need to add another allowed app (say your company adopts a new tool that should be allowed to access corp data), just edit the App Protection Policy in Intune and add that app to the protected list. Policy updates apply near-real-time to usage. Removing an app from allowed list effectively immediately prevents it from opening new corporate data (though any already saved corporate data in that app would remain encrypted and inaccessible). If an employee leaves, removing their account or wiping corporate data from their device is possible from Intune (App Protection has a wipe function that will remove corporate data from the apps on the next launch).
Summary of MAM Approach: With Intune MAM, the app itself isn’t blocked from running, but it’s blocked from accessing any company info[1][1]. This is ideal if you don’t manage the entire device, such as personal devices. Even if a user installs an unapproved app, it cannot touch work data – making it effectively useless for work. The user retains the freedom to use their device for personal tasks, while IT ensures corporate data stays confined to secure apps[1][1]. This approach requires less device control and is generally more palatable for users worried about privacy on their own machines[1]. The trade-off is that it doesn’t prevent all risks (a user could still run risky software on their personal device – it just won’t have company data to abuse)[1][1].
Comparison of MDM vs MAM Approaches
To summarize the differences between the device-based blocking (MDM/AppLocker) and app-based blocking (MAM/App Protection) approach, consider the following comparison:
What is blocked: MDM completely blocks the application from launching on the device – the user clicks it, and nothing happens (or gets a “blocked by admin” notice)[1][1]. MAM allows the app to run, but blocks access to any protected (corp) data. The app can launch and be used for personal things, but if it tries to access work files or data, that access is denied or the data is unreadable[1][1].
Use case: MDM is best for company-owned devices under IT control where you want to outright ban certain software for security, licensing, or productivity reasons[1]. MAM is best for personal/BYOD devices (or to add a second layer on corporate devices) where you can’t or don’t want full control over the device, but still need to protect corporate information[1][1].
Implementation effort: MDM/Applocker requires a more technical setup initially (creating rules, exporting XML, etc.) – but once in place, it’s mostly “set and forget”, with occasional updates to the XML for changes[1][1]. It does require devices to be enrolled and on supported Windows editions[1]. MAM is configured through Intune’s UI (selecting apps and settings), which is a bit more straightforward. However, to be fully effective, you also need to configure Conditional Access, which can be complex to get right[1][1]. MAM doesn’t require device enrollment, just Azure AD sign-in.
User experience: With MDM blocking, if a user tries to open the app, it will not run at all. This could potentially disrupt work if, say, an important app was accidentally blocked – but otherwise the enforcement is silent/invisible until they actually try the blocked app[1][1]. With MAM, the user might see some prompts or restrictions in effect (like copy/paste blocked, or a message “your org protects data in this app”)[1][1]. Personal use of the device is unaffected, only when they deal with work data they encounter restrictions. This usually necessitates a bit of user education so they understand why certain actions are blocked[1][1].
Security strength: MDM’s AppLocker is very strong at preventing the app from causing any trouble on that device – if the app is malware or a forbidden tool, it simply can’t run[1][1]. It also means you could lockdown a device to only a whitelisted set of apps if you wanted (kiosk mode scenarios). MAM is very strong for data loss prevention – corporate content won’t leak to unapproved apps or cloud services[1][1]. However, it doesn’t stop a user from installing something risky on their own device for personal use (that risk is mitigated only to the extent that company data isn’t exposed). So to fully cover security, an enterprise might use MDM+MAM combined (MDM for device posture, antivirus, etc., and MAM for data protection on the edge cases).
Privacy impact: MDM is high impact on user privacy – IT can control many aspects of the device (and even wipe it entirely). So employees might resist MDM on personal devices[1][1]. MAM is low impact – it doesn’t touch personal files or apps at all, only corporate data within certain apps is managed[1][1]. If someone leaves the company, IT can remotely wipe the corporate data in the apps, but their personal stuff stays intact[1].
Licensing considerations: Both approaches are fully supported in M365 Business Premium. MDM with AppLocker needs Windows 10/11 Pro or higher (which Business Premium covers via Windows Business, essentially Pro)[1][1]. MAM for Windows needs Azure AD Premium (for CA) and Intune, which are included in Business Premium[1][1]. No extra licensing is needed unless you want advanced features like Defender for Endpoint P2 or Purview DLP in the future.
Additional Tips and Resources
Use Intune Reporting: Regularly check Intune’s Discovered Apps report (in Endpoint Manager under Apps > Monitor > Discovered apps). This report shows what software is found on your managed devices[3]. It can help identify if users have installed something that should be blocked, or to verify that a banned app is indeed not present.
Stay Informed on Updates: Intune and Windows are evolving. For example, new features like “App Control for Business” (a simplified interface for application control in Intune) or changes to WIP deprecation may come. Keep an eye on Microsoft 365 roadmap and Intune release notes so you can adapt your approach.
Training and Communication: Ensure that your IT support staff know how the policies work, so they can assist users. For instance, if a user tries to use a blocked app, the helpdesk should be able to explain “That application isn’t allowed by company policy” and suggest an approved alternative. Provide employees with a list of approved software and explain the process to request new software if needed (so they don’t attempt to install random tools).
The Microsoft Tech Community and Q\&A forums have real-world Q\&As. For example, handling removal of a stuck AppLocker policy was discussed in a community question[2][2].
The Microsoft Intune Customer Success blog has a post on “Blocking and removing apps on Intune managed devices” (Feb 2025) which provides guidance using a real example (blocking the DeepSeek AI app) across different platforms[4]. It’s a good supplemental read for advanced scenarios and cross-platform considerations.
Compliance and Legal: If your blocking is driven by compliance (e.g., a government ban on an app), ensure you archive proof of compliance. Intune logs and reports showing the policy applied can serve as evidence that you took required action. Also ensure your Acceptable Use Policy given to employees clearly states that certain applications are prohibited on work devices — this helps cover legal bases and user expectations.
Conclusion
With Microsoft 365 Business Premium, you have robust tools to control application usage on Windows devices. By leveraging Intune MDM with AppLocker, you can completely block unauthorized applications from running on company PCs, thereby enhancing security and productivity. The detailed steps above guide you through creating and deploying such a policy in a manageable way. Additionally, Intune’s App Protection (MAM) capabilities offer a complementary solution for protecting corporate data on devices you don’t fully manage, ensuring that even in BYOD situations, sensitive information remains in sanctioned apps.
In practice, many organizations will use a blend: e.g., require MDM for corporate laptops (where you enforce AppLocker to ban high-risk apps) and use MAM for any personal devices that access company data. The most effective method ultimately depends on your scenario, but with MDM and MAM at your disposal, M365 Business Premium provides a comprehensive toolkit to block or mitigate unapproved applications. By following the step-by-step processes and best practices outlined in this guide, IT administrators can confidently enforce application policies and adapt them as the organization’s needs evolve, all while keeping user impact and security compliance in balance.